Samsung AI Researchers Introduce Neural Haircut: A Novel AI Method to Reconstruct Strand-based Geometry of Human Hair from Video or Images
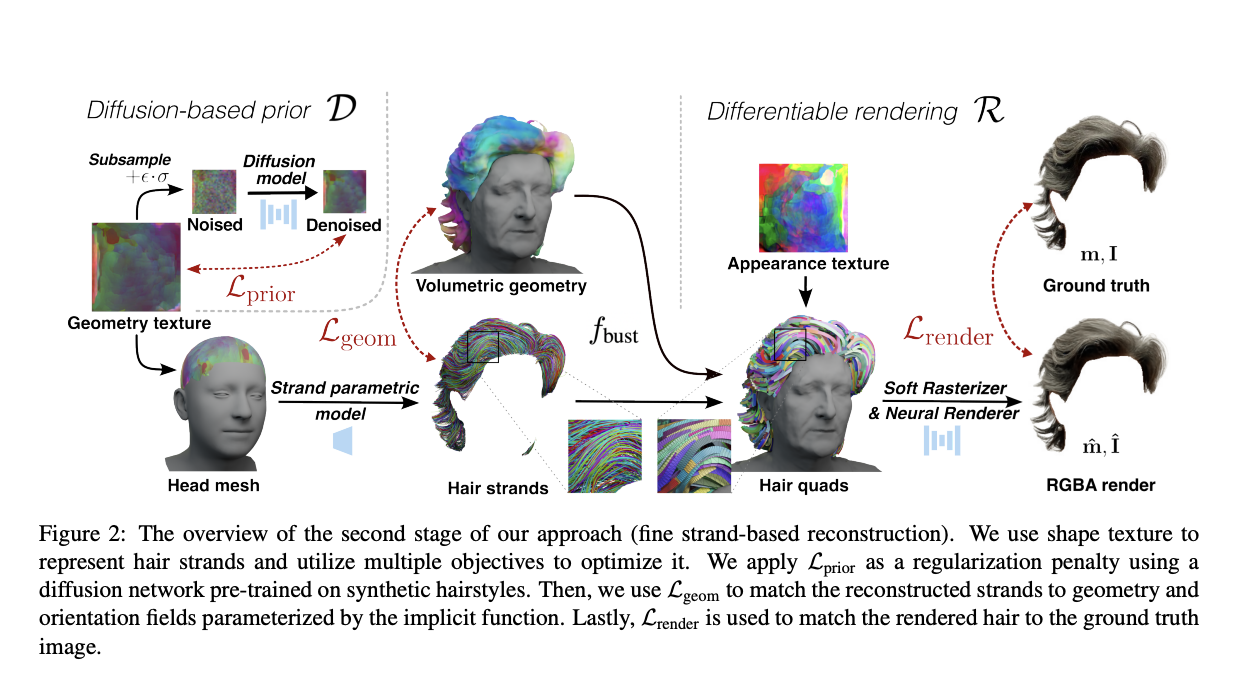
Researchers from Samsung AI Center, Rockstar Games, FAU Erlangen-Nurnberg, and Cinemersive Labs suggest a brand-new technique for image-based modeling that can extract human hair from several views of photos or video frames. Due to its very complicated geometry, physics, and reflectance, hair reconstruction is one of the most difficult tasks in human 3D modeling. Nevertheless, it is essential for many applications, including gaming, telepresence, and special effects. 3D polylines, or strands, are the most popular way to depict hair in computer graphics since they can be used for physics modeling and realistic rendering. Modern image- and video-based systems for reconstructing humans frequently simulate hairstyles using data structures with fewer degrees of freedom that are simpler to estimate, including volumetric representations or meshes with set topologies.
As a result, these techniques frequently produce overly smoothed hair geometries, and they can only accurately represent the “outer shell” of a hairstyle without capturing its core structure. Using light stages, controlled lighting equipment, and a dense capture system with synchronized cameras, it is possible to do accurate strand-based hair reconstruction. Recently, depending on organized or consistent illumination and camera calibration to speed up the reconstruction process yielded amazing results. The most recent effort also used manual frame-wise annotation of the hair growth directions to produce physically credible reconstructions. The complex capture setup and laborious pre-processing requirements make such technologies impractical for many practical applications despite the outstanding quality of the findings.

Several learning-based algorithms for hairstyle modeling use hair priors discovered from the strand-based synthetic data to speed up the acquisition process. However, the quantity of the training dataset is a natural determinant of these approaches’ accuracy. Since most existing datasets only contain a few hundred samples, they need to be bigger to appropriately handle the variety of human hairstyles, which results in low reconstruction quality. This study provides a technique for hair modeling that operates in uncontrolled lighting settings and needs image- or video-based data without any further user annotations. They have created a two-stage reconstruction process to do that. Coarse volumetric hair restoration in the first step is entirely data-driven and uses implicit volumetric representations. The second step, known as fine strand-based reconstruction, works at the level of individual hair strands and mainly depends on priors discovered from a tiny synthetic dataset. For the hair and bust (head and shoulders) areas, they recreate implicit surface representations during the first step.
Additionally, by comparing them with hair directions shown in the training pictures or 2D orientation maps using a differentiable projection, they can learn a field of hair growth directions that they refer to as 3D orientations. Although this field can help with a more precise fitting of the hair form, its main application is to limit the second stage’s optimization of the hair strands. They employ a traditional method based on picture gradients to generate the hair orientation maps from the input frames.
To produce strand-based reconstructions, the second stage uses pre-trained priors. They use an enhanced parametric model trained from the synthetic data using an auto-encoder to represent individual hair strands and their joint distribution or the entire hairstyle. Thus, through an optimization procedure, this stage reconciles the coarse hair reconstruction achieved in the previous stage with the learning-based priors. Finally, they use a novel hair renderer based on soft rasterization to increase the realism of the rebuilt hairstyles using differentiable rendering.
In summary, their contributions include:
• An improved training approach for the strand prior
• A human head 3D reconstruction method for the breast and hair regions that includes hair orientations
• Global hairstyle modeling using a latent diffusion-based prior that “interfaces” with a parametric strand prior
• Differentiable soft hair rasterization methodology that produces more precise reconstructions than earlier rendering techniques.
• The strand-fitting method combines all the elements mentioned above to make excellent reconstructions of human hair at the strand level.
They employ monocular films from a smartphone and multi-view photos from a 3D scanner operating in unrestricted illumination settings to test the effectiveness of their technique on artificial and real-world data.
Check out the Paper, Github, and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.