Detecting Alcohol Exposure in Media: Evaluating the Power of CLIP’s Zero-Shot Learning vs. ABIDLA2 Deep Learning in Image Analysis
Alcohol, a prevalent health concern, represents 5.1% of the global burden of disease, causing a significant negative impact on individuals and the economy. From social media to films, advertising, and popular music, alcohol exposure is everywhere. Researchers suggest a link between exposure to alcohol-related social media posts and alcohol use, particularly among young adults. The researchers are exploring innovative approaches to measure and analyze alcohol exposure. Supervised deep learning models like Alcoholic Beverage Identification Deep Learning Algorithm (ABIDLA) have shown promise in identifying alcoholic beverages from images but require a vast amount of manually annotated data for training.
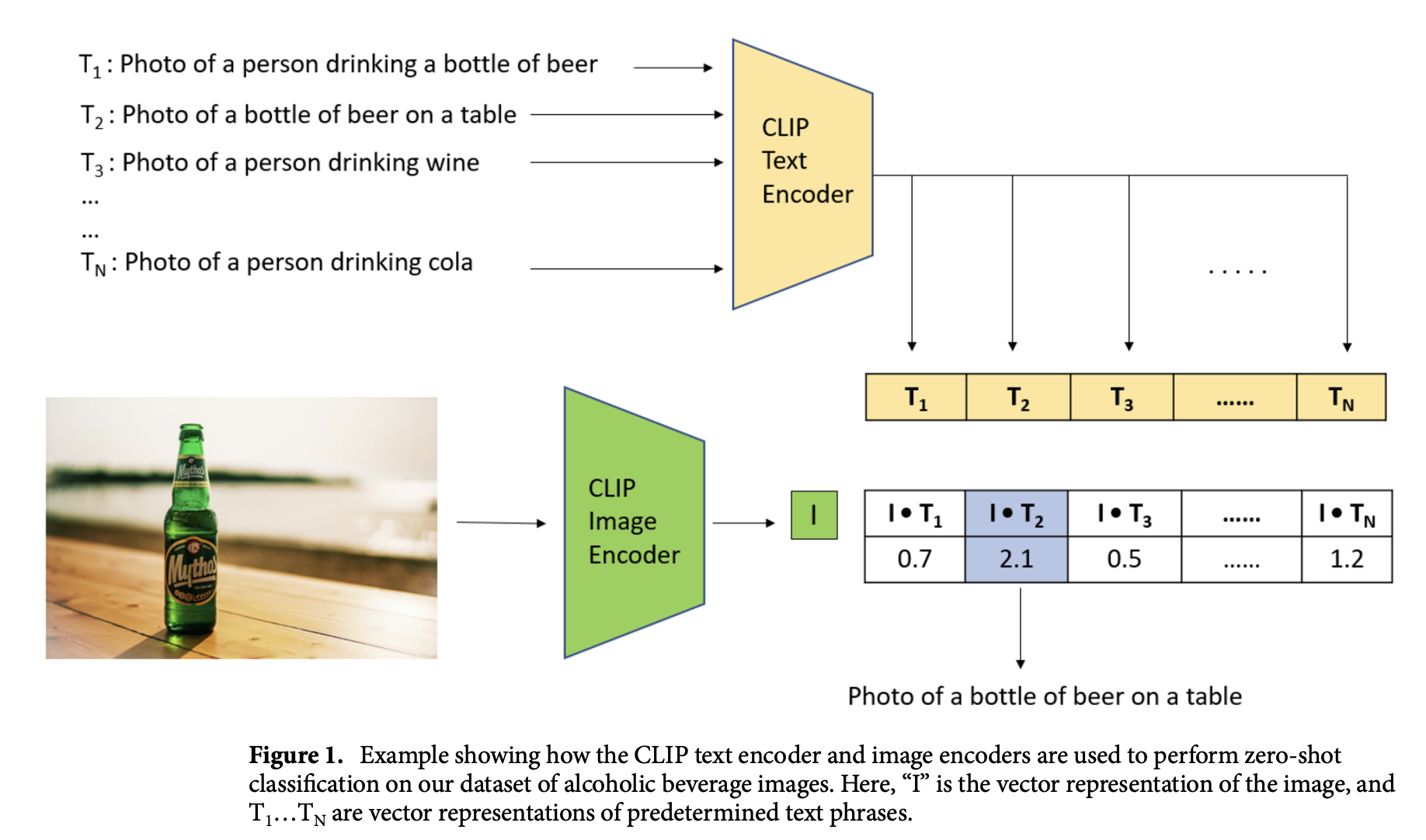
An alternating approach to this is Zero-Shot Learning (ZSL) utilizing the Contrastive Language-Image Pretraining (CLIP) model. The researchers have investigated the performance of a ZSL model compared to a deep learning algorithm specifically trained to identify alcoholic beverages in images (ABIDLA2). The test dataset used by research scholars for evaluation is used in the ABIDLA2 paper, ABD22, containing eight beverage categories. The testing set has 1762 per class to maintain a uniform distribution for evaluation. The evaluation involves three tasks, and the performance metrics, such as unweighted average recall (UAR), F1 score, and per-class recall, were computed and compared for ABIDLA2 and ZSL for both named and descriptive phrases.
The researchers found that ZSL performed well in some tasks but needed help with fine-grained classification. The ABIDLA2 model outperformed ZSL in identifying specific beverage categories. However, ZSL using descriptive phrases (e.g., “this is a picture of someone holding a beer bottle”) performed nearly as well as ABIDLA2 on classifying specific beverages into broader beverage categories (beer, wine, spirits, and others, i.e., Task 2) and even surpassed ABIDLA2 when classifying whether a picture included alcohol content or not.
They identified that phrase engineering is essential for ZSL to achieve higher performance, especially for the ‘others’ class.
One of the key strengths of this work is that ZSL requires minimal additional training data and computational resources and less computer science expertise compared to the supervised learning algorithm. It can accurately address research questions such as identifying alcohol content in images, especially when binary classification is required. The findings encourage future works to compare the generalization capability of supervised learning models to ZSL on real-life datasets that include images of different populations and cultures.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Astha Kumari is a consulting intern at MarktechPost. She is currently pursuing Dual degree course in the department of chemical engineering from Indian Institute of Technology(IIT), Kharagpur. She is a machine learning and artificial intelligence enthusiast. She is keen in exploring their real life applications in various fields.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.