Google DeepMind and the University of Tokyo Researchers Introduce WebAgent: An LLM-Driven Agent that can Complete the Tasks on Real Websites Following Natural Language Instructions
Several natural language activities, including arithmetic, common sense, logical reasoning, question-and-answer tasks, text production, and even interactive decision-making tasks, may be solved using large language models (LLM). By utilizing the ability of HTML comprehension and multi-step reasoning, LLMs have recently shown excellent success in autonomous web navigation, where the agents control computers or browse the internet to satisfy the given natural language instructions through the sequence of computer actions. The absence of a preset action space, the lengthier HTML observations compared to simulators, and the lack of HTML domain knowledge in LLMs have all negatively impacted web navigation on real-world websites (Figure 1).
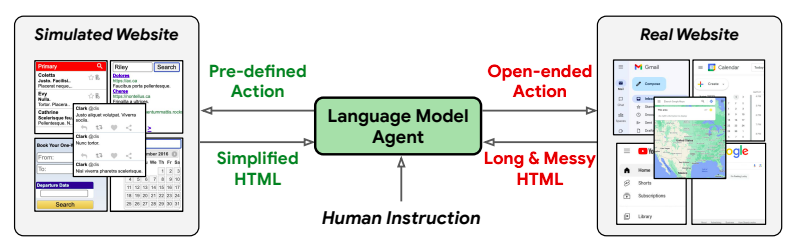
Given the intricacy of instructions and open-ended real-world websites, it cannot be easy to choose the right action space in advance. The latest LLMs only sometimes have optimum designs for processing HTML texts, even though various research studies have claimed that instruction-finetuning or reinforcement learning from human input increases HTML understanding and accuracy of online navigation. Most LLMs prioritize wide task generalization and model-size scalability by prioritizing shorter context durations compared to the typical HTML tokens found in real webpages and by not adopting past approaches for structured documents, including text-XPath alignment and text-HTML token separation.
Even applying token-level alignments to such lengthy texts would be relatively inexpensive. By grouping canonical web operations in program space, they offer WebAgent, an LLM-driven autonomous agent that can carry out navigation tasks on actual websites while adhering to human commands. By breaking down natural language instructions into smaller steps, WebAgent:
- Plans sub-instructions for each step.
- Condenses lengthy HTML pages into task-relevant snippets based on sub-instructions.
- Executes sub-instructions and HTML snippets on actual websites.
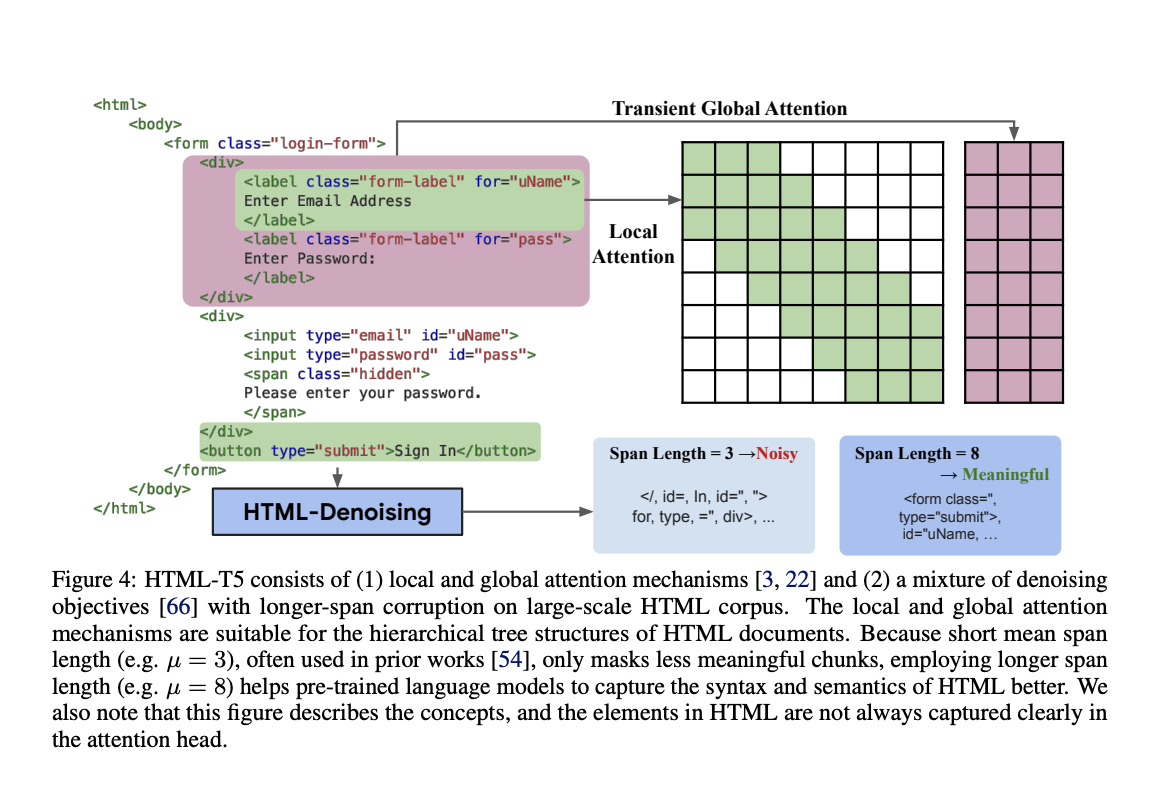
In this study researchers from Google DeepMind and The University of Tokyo combine two LLMs to create WebAgent: The recently created HTML-T5, a domain-expert pre-trained language model, is used for work planning and conditional HTML summarization. Flan-U-PaLM is used for grounded code generation. By including local and global attention methods in the encoder, HTML-T5 is specialized to capture better the structure syntax and semantics of lengthy HTML pages. It is self-supervised, pre-trained on a sizable HTML corpus created by CommonCrawl1 using a combination of long-span denoising objectives. Existing LLM-driven agents frequently complete decision-making tasks using a single LLM to prompt various examples for each job. However, this is insufficient for real-world tasks because their complexity exceeds that of simulators.
According to thorough assessments, their integrated strategy with plugin language models increases HTML comprehension and grounding and delivers greater generalization. Thorough research shows that linking task planning with HTML summary in specialized language models is crucial for task performance, increasing the success rate on real-world online navigation by over 50%. WebAgent outperforms single LLMs on static website comprehension tasks regarding QA accuracy and has comparable performance against sound baselines. Additionally, HTML-T5 functions as a key plugin for WebAgent and independently produces cutting-edge outcomes on web-based jobs. On the MiniWoB++ test, HTML-T5 outperforms naïve local-global attention models and its instruction-finetuned variations, achieving 14.9% more success than the previous best technique.
They have mostly contributed to:
• They provide WebAgent, which combines two LLMs for practical web navigation. The generalist language model produces executable programs, whereas the domain expert language model handles planning and HTML summaries.
• By adopting local-global attentions and pre-training using a combination of long-span denoising on large-scale HTML corpora, they provide HTML-T5, new HTML-specific language models.
• In the real website, HTML-T5 significantly increases success rates by over 50%, and in MiniWoB++, it surpasses previous LLM agents by 14.9%.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.