Meet MC-JEPA: A Joint-Embedding Predictive Architecture for Self-Supervised Learning of Motion and Content Features
Recently, techniques focusing on learning content features—specifically, features holding the information that lets us identify and discriminate objects—have dominated self-supervised learning in vision. Most techniques concentrate on identifying broad characteristics that perform well in tasks like item categorization or activity detection in films. Learning localized features that excel at regional tasks like segmentation and detection is a relatively recent concept. However, these techniques concentrate on comprehending the content of pictures and videos rather than being able to learn characteristics about pixels, such as motion in films or textures.
In this research, authors from Meta AI, PSL Research University, and New York University concentrate on simultaneously learning content characteristics with generic self-supervised learning and motion features utilizing self-supervised optical flow estimates from movies as a pretext problem. When two pictures—for example, successive frames in a movie or images from a stereo pair—move or have a dense pixel connection, it is captured by optical flow. In computer vision, estimating is a basic problem whose resolution is essential to operations like visual odometry, depth estimation, or object tracking. According to traditional methods, estimating optical flow is an optimization issue that aims to match pixels with a smoothness requirement.
The challenge of categorizing real-world data instead of synthetic data limits approaches based on neural networks and supervised learning. Self-supervised techniques now compete with supervised techniques by allowing learning from substantial amounts of real-world video data. The majority of current approaches, however, only pay attention to motion rather than the (semantic) content of the video. This issue is resolved by simultaneously learning motion and content elements in pictures using a multi-task approach. Recent methods identify spatial relationships between video frames. The objective is to follow the movement of objects to collect content data that optical flow estimates cannot.
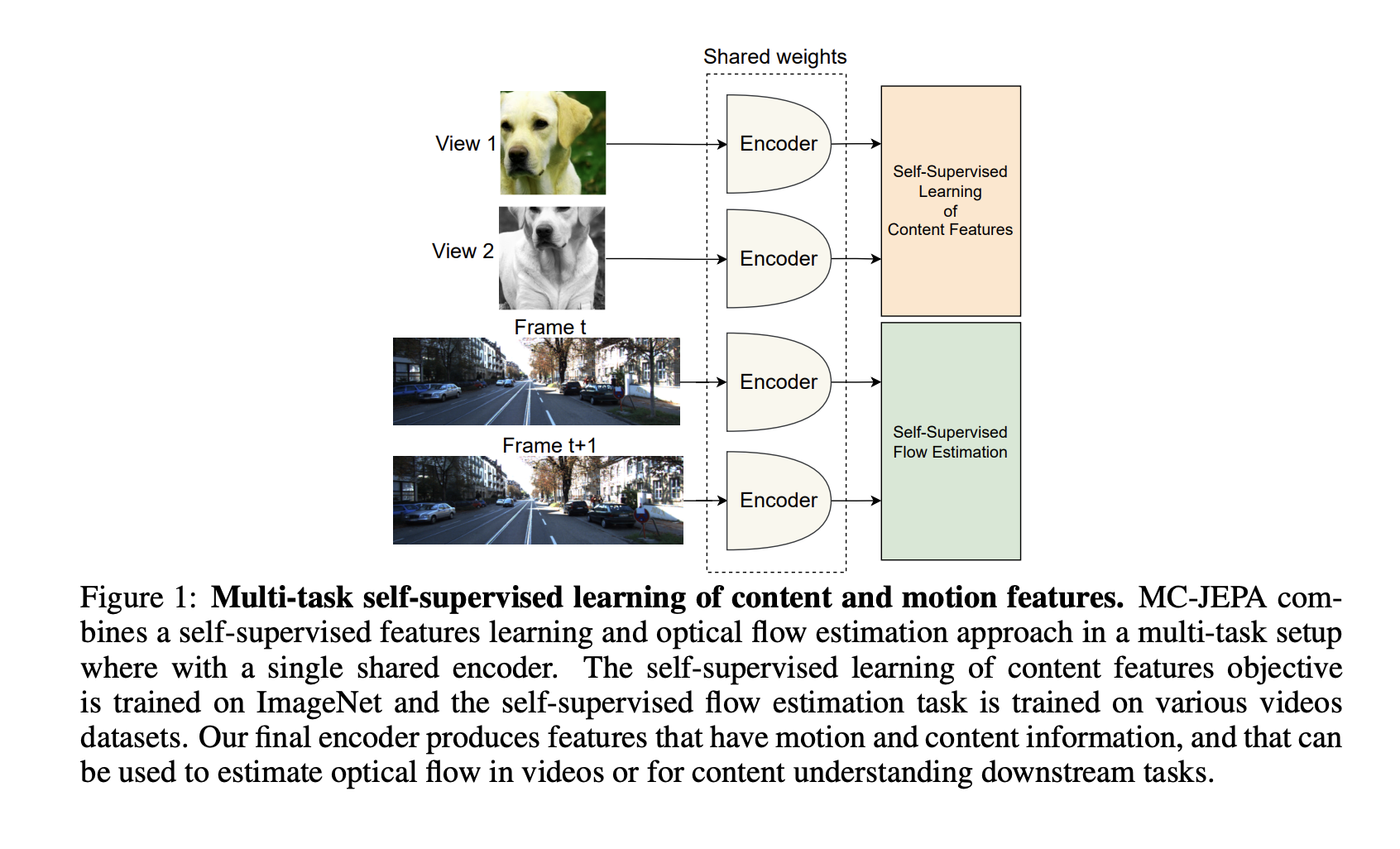
These methods are object-level motion estimation methods. With relatively weak generalization to other visual downstream tasks, they acquire highly specialized characteristics for the tracking job. The low quality of the visual characteristics learned is reinforced by the fact that they are frequently trained on tiny video datasets that need more diversity than larger picture datasets like ImageNet. Learning several activities simultaneously is a more reliable technique for developing visual representations. To solve this problem, they offer MC-JEPA (Motion-Content Joint-Embedding Predictive Architecture). Using a common encoder, this joint-embedding-predictive architecture-based system learns optical flow estimates and content characteristics in a multi-task environment.
The following is a summary of their contributions:
• They offer a technique based on PWC-Net that is augmented with numerous extra elements, such as a backward consistency loss and a variance-covariance regularisation term, for learning self-supervised optical flow from synthetic and real video data.
• They use M-JEPA with VICReg, a self-supervised learning technique trained on ImageNet, in a multi-task configuration to optimize their estimated flow and provide content characteristics that transfer well to several downstream tasks. The name of their ultimate approach is MC-JEPA.
• They tested MC-JEPA on a variety of optical flow benchmarks, including KITTI 2015 and Sintel, as well as image and video segmentation tasks on Cityscapes or DAVIS, and they found that a single encoder performed well on each of these tasks. They anticipate that MC-JEPA will be a precursor to self-supervised learning methodologies based on joint embedding and multi-task learning that can be trained on any visual data, including images and videos, and perform well across various tasks, from motion prediction to content understanding.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.