Large Language Models as Tax Attorneys: This AI Paper Explores LLM Capabilities in Applying Tax Law
Advances in AI are being made. Large Language Models (LLMs) are where the quick advancements are happening. Modern LLMs can use tools, plan, and pass standardized assessments. But even to its creators, LLMs are simply mysterious boxes. They don’t know much about how they think inside and can’t predict how an LLM would act in a new situation. Before models are used outside the research setting, it is best practice to assess LLM performance on a long list of benchmarks. However, these benchmarks frequently need to reflect real-world activities that are important to us or may have been memorized by the LLM during training. The data required for performance evaluation is commonly included in the datasets used for training LLMs, which are frequently downloaded from the internet.
The overlap may overestimate the model’s performance, creating the impression of comprehension when it may only be simple recognition. They especially concentrate their evaluation efforts on the LLMs’ legal analytical skills for three reasons. First, determining how well LLMs understand the law can help with more general regulation of LLMs and automated systems. One policy-relevant strategy is to utilize legal and regulatory reasoning in LLMs for “Law-Informed AI” that aligns with societal ideals established via democratic procedures and lawmaking. This “Law Informs Code” strategy is based on the democratic process’s demonstrated ability to produce flexible legal norms like fiduciary obligations through iterative deliberation and litigation. The idea is that teaching AI systems the spirit of the law can help them make defensible decisions in unfamiliar situations. When an LLM-powered system supports a human principle, this early capacity to detect when fiduciary responsibilities are broken might enable safer AI deployments. Second, whether through self-service or a qualified attorney, LLMs may be utilized as instruments by people to deliver legal services more quickly and effectively. The models may be more dependable and valuable if they better comprehend the law. LLMs may help with various activities, from case prediction to contract analysis, thereby democratizing access to legal assistance and lowering the cost and complexity for individuals who might otherwise find it difficult to understand the legal system.
Given the delicate nature of legal work, certain protections should be implemented as these models are implemented. This entails improving data privacy, reducing bias, upholding responsibility for these models’ choices, and assessing the LLMs’ applicability for a particular use case. Thus, systematic evaluations are necessary. Third, if LLMs have sufficient legal knowledge, they may be used by the government, people, and scholars to spot legal contradictions. LLMs may improve the overall effectiveness and openness of governments. For instance, LLMs frequently can explain complicated rules and regulations in a way that is both clear and intelligible.
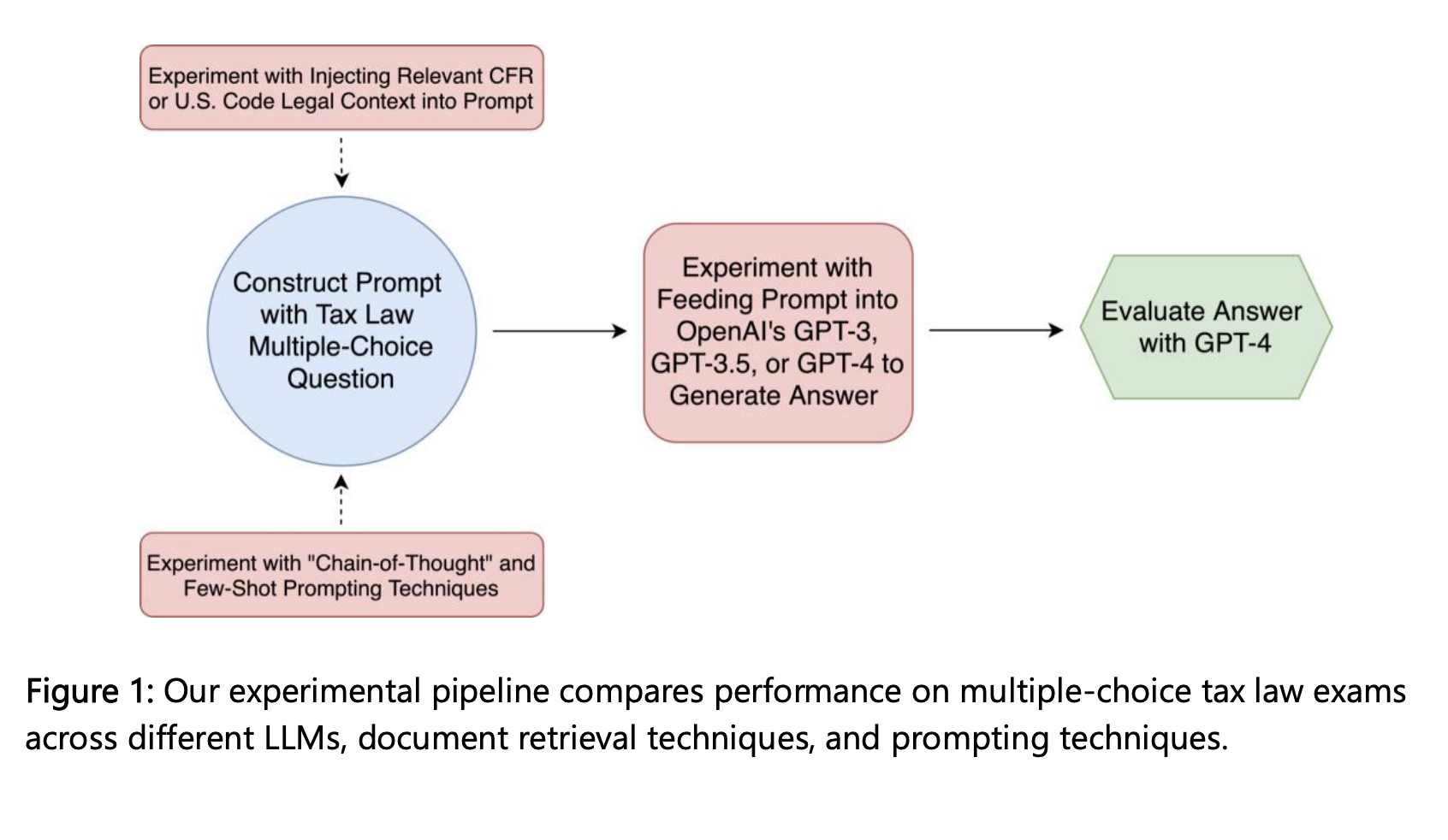
In the future, LLMs can forecast the probable effects of new laws or policies. LLMs might identify possibly “outdated” legislation or situations where the law is silent when, in other comparable cases, the legislature or regulators give guidance by scanning enormous quantities of legal language and accompanying implementations. In this research, researchers from Stanford University, University of Michigan, University of Washington, University of Southern California, Northwestern Pritzker School of Law and SimPPL investigate the retrieval-augmented creation of LLMs using the text of the U.S. Code (a collection of federal legislation) and the U.S. Code of Federal Regulations (CFR). They evaluate a group of LLMs’ developing comprehension of tax law. They decided on tax law for four factors.
The legal authority in tax law is mostly contained in two sources: the Treasury Regulations under the CFR and Title 26 of the U.S. Code (commonly known as the Internal Revenue Code). This contrasts several legal areas where the doctrines are distilled from multiple precedents. This enables us to supplement the retrieval of the LLM using a predefined universe of possibly pertinent documents. Second, a lot of tax laws permit conclusive responses to questions. This enables us to put up automatic validation workflows that are consistent. Third, addressing tax law questions for a specific case typically needs more than merely reading the pertinent legal authority; hence, they can assess LLM competencies in a way that applies to real-world practice.
Fourth, tax law has a considerable impact on practically every citizen’s and company’s daily economic activities. With the help of several experimental setups, including the use of the LLM alone, the integration of the LLM with the underlying legal texts, and various retrieval techniques (with comparisons made across different retrieval methods), we evaluate the accuracy of responses produced by LLMs on thousands of tax law inquiries. We do these tests on a range of LLMs, from the smallest and weakest models all the way up to the biggest modern model, OpenAI’s GPT-4. Each LLM we examined was cutting-edge when it was first made available.
They discover evidence for developing legal understanding capacities of LLMs, improving with each model release by analyzing outcomes across progressively bigger models. If technology continues to grow quickly, they may soon witness the development of superhuman AI legal abilities.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.