Meet Med-Flamingo: A Unique Foundation Model which is Capable of Performing Multimodal in-context Learning Specialized for the Medical Domain
With the increasing popularity of Artificial Intelligence (AI), foundation models have demonstrated an amazing ability to handle a variety of problems with only a small amount of information provided by labeled instances. The idea of in-context learning has gained attention with its ability to let a model pick up a task from a few examples given while being prompted without adjusting the model’s parameters. Considering the field of healthcare and the medical domain, in-context learning has the potential to improve current medical AI models exponentially.
Though in-context learning has shown some great capabilities in terms of medical data, due to the intrinsic complexity and multimodality of medical data, as well as the variety of tasks that must be accomplished, implementing in-context learning in a medical setting offers difficulties. Multimodal medical foundation models have been attempted in the past, such as ChexZero, which specializes in reading chest X-rays, and BiomedCLIP, which was trained on a variety of images linked with captions from biological literature. For surgical footage and electronic health record (EHR) data, several models have been devised. None of these models have included contextual learning for the multimodal medical domain.
To address the limitations, a team of researchers has proposed Med-Flamingo, a unique and highly effective foundation model that is capable of performing multimodal in-context learning specialized for the medical domain. This vision-language model is based on Flamingo, which is one of the first vision-language models that demonstrate in-context learning and few-shot learning capabilities. By providing pre-training in multimodal knowledge sources from multiple medical fields, Med-Flamingo expands these capabilities to the medical arena.
The first phase entails creating an original, interleaved image-text dataset from over 4K medical textbooks, assuring correctness by selecting the dataset from reputable and reliable sources of medical knowledge. In order to evaluate Med-Flamingo, the researchers have focussed on generative medical visual question-answering (VQA) tasks, where the model directly creates open-ended responses rather than assessing pre-defined possibilities. A new and realistic evaluation process has been developed that yields a human evaluation score as the key parameter. A visual USMLE dataset has also been developed, which is a difficult generative VQA dataset comprising difficult USMLE-style tasks across specialties, enhanced with images, case vignettes, and lab results.
In three generative medical VQA datasets, Med-Flamingo has been shown to outperform earlier models in clinical evaluation scores, suggesting that doctors favor the model’s predictions. It has exhibited medical reasoning skills, something multimodal medical foundation models have not previously done, by responding to complicated medical queries and offering justifications. The model’s effectiveness can, though, be constrained by the variety and accessibility of the training data as well as the difficulty of some medical tasks.
The team has summarized their contributions as follows.
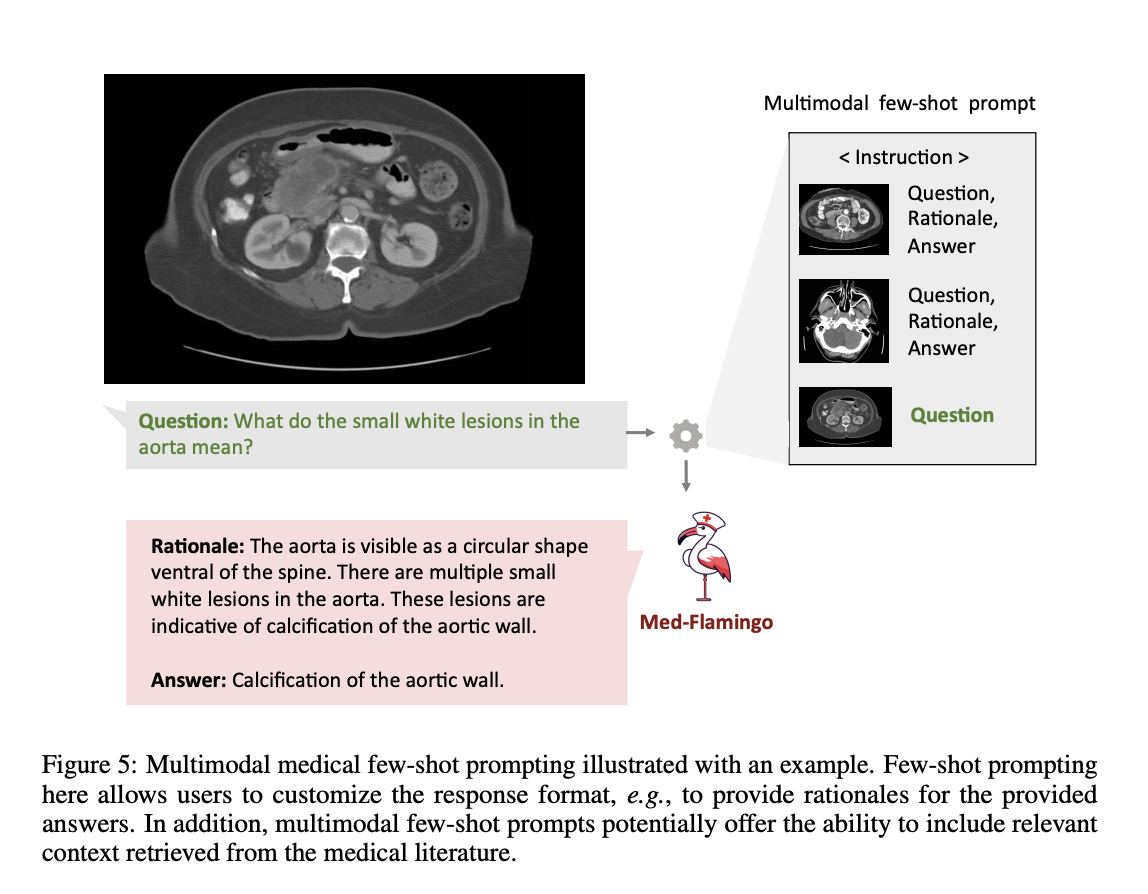
- Med-Flamingo is the first multimodal few-shot learner designed for the medical domain, offering new clinical applications like rationale generation and context conditioning.
- The researchers have built a unique dataset for pre-training the model, specifically suited for multimodal few-shot learning in the medical domain.
- They have also introduced an evaluation dataset with USMLE-style problems, incorporating complex medical reasoning in visual question answering.
- Existing evaluation strategies are critiqued, and an in-depth clinical evaluation study has been conducted using a dedicated app involving medical raters to assess the model’s open-ended VQA generations.
Check out the Paper, Model, and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.