Abacus AI Introduces A New Open Long-Context Large Language Model LLM: Meet Giraffe
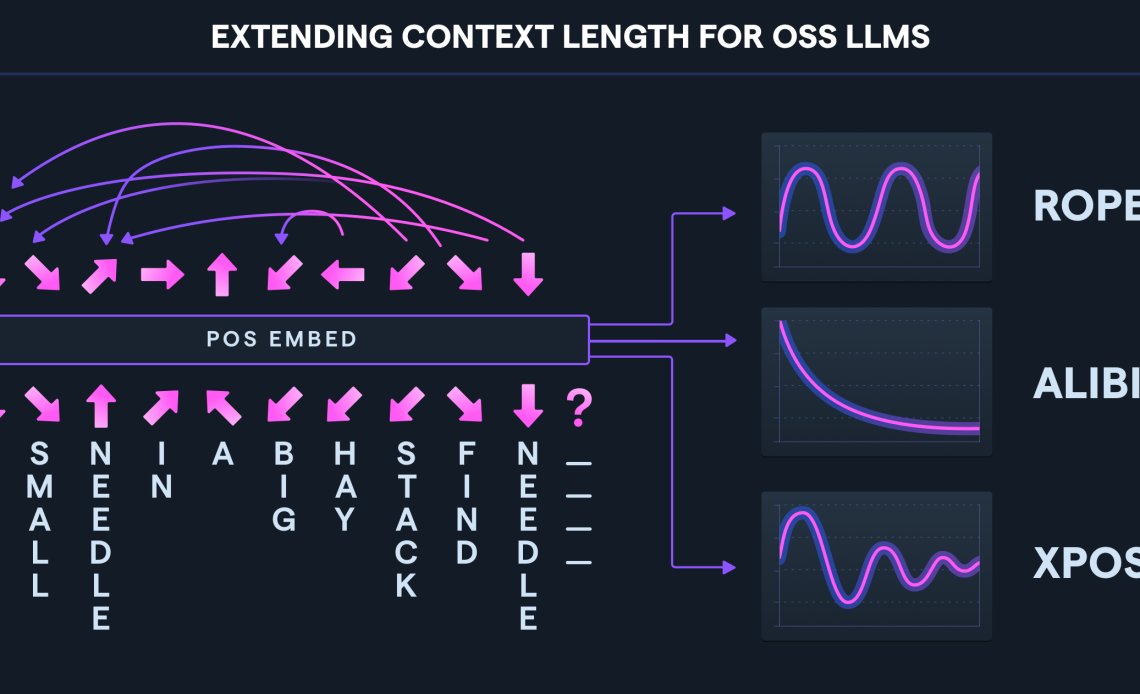
Recent language models can take long contexts as input; more is needed to know about how well they use longer contexts. Can LLMs be extended to longer contexts? This is an unanswered question. Researchers at Abacus AI conducted multiple experiments involving different schemes for developing the context length ability of Llama, which is pre-trained on context length 2048. They linear rescaled these models with IFT at scales 4 and 16. Scaling the model to scale 16 can perform world tasks up to 16k context length or even up to 20-24k context length.
Different methods of extending context length are Linear scaling, scaling the Fourier basis of Rotatory Position Embedding (RoPE) by a power, truncating the Fourier basis, and randomizing the position vector. Researchers at Abacus AI fine-tuned the RedPajama dataset combined with the Vicuna dataset by implementing the above methods. They found that Linear scaling was robust but increased the model context length. Truncation and randomization have great perplexity scores but performed less on the retrieval task.
To evaluate these models, researchers used datasets from LMSys, open-book question-answering datasets, and WikiQA. LMSys datasets were used for locating a substring in the context. WikiQA task is the task of answering a question based on the information given in a Wikipedia document.
The team constructed a QA task based on the short answer format data in Google Natural Questions. They assured that the output is just a short-word answer copy-pasted from the original document. This allows to pinpoint exactly where the LLM is supposed to look and effectively evaluate every part of the expanded context length by placing the answer in different locations. They also created multiple versions of the same Wikipedia document with varying sizes, which allowed them to obtain fair evaluation across model sizes.
The issue with the Wikipedia-based dataset is that the model answered from its pre-trained written texts rather than from the context. Researchers resolved this by creating an altered dataset consisting of questions with only numerical answers. They altered the answers and every occurrence of the response in the document to a different number. This will make the model incorrectly answer if LLM recollects from its pre-trained texts. They named the original QA task Free Form QA ( FFQA ) and the altered task Altered Numerical QA (AltQA).
Researchers at AbacusAI evaluated the Presence Accuracy on every example in both versions of QA tasks. Presence Accuracy is measured whether or not the answer is present as a substring in the model’s generated solution. They observed that an increase in accuracy by IFT doesn’t confer any extension to the range of context lengths the model can achieve.
Researchers show that IFT with scaled context leads to a significant jump in performance. They observed a 2x improvement in FFQA and a 2.5x improvement in AltQA at all positions interpolated by the scale context factor. Finally, their research work suggests a larger-context language model, which improves perplexity because it captures the theme of a document better and more easily.
Check out the GitHub and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.