Meet MovieChat: An Innovative Video Understanding System that Integrates Video Foundation Models and Large Language Models
Large Language Models (LLMs) have recently made considerable strides in the Natural Language Processing (NLP) sector. Adding multi-modality to LLMs and transforming them into Multimodal Large Language Models (MLLMs), which can perform multimodal perception and interpretation, is a logical step. As a possible step towards Artificial General Intelligence (AGI), MLLMs have demonstrated astounding emergent skills in various multimodal tasks like perception (e.g., existence, count, location, OCR), commonsense reasoning, and code reasoning. MLLMs offer a more human-like perspective of the environment, a user-friendly interface for interaction, and a wider range of task-solving skills compared to LLMs and other task-specific models.
Existing vision-centric MLLMs use the Q-former or basic projection layer, pre-trained LLMs, a visual encoder, and extra learnable modules. A different paradigm combines current visual perception tools (such as tracking and classification) with LLMs through API to construct a system without training. Some earlier studies in the video sector developed video MLLMs using this paradigm. However, there had never been any investigation of a model or system based on lengthy movies (those lasting longer than a minute), and there had never been set criteria against which to measure the effectiveness of these systems.
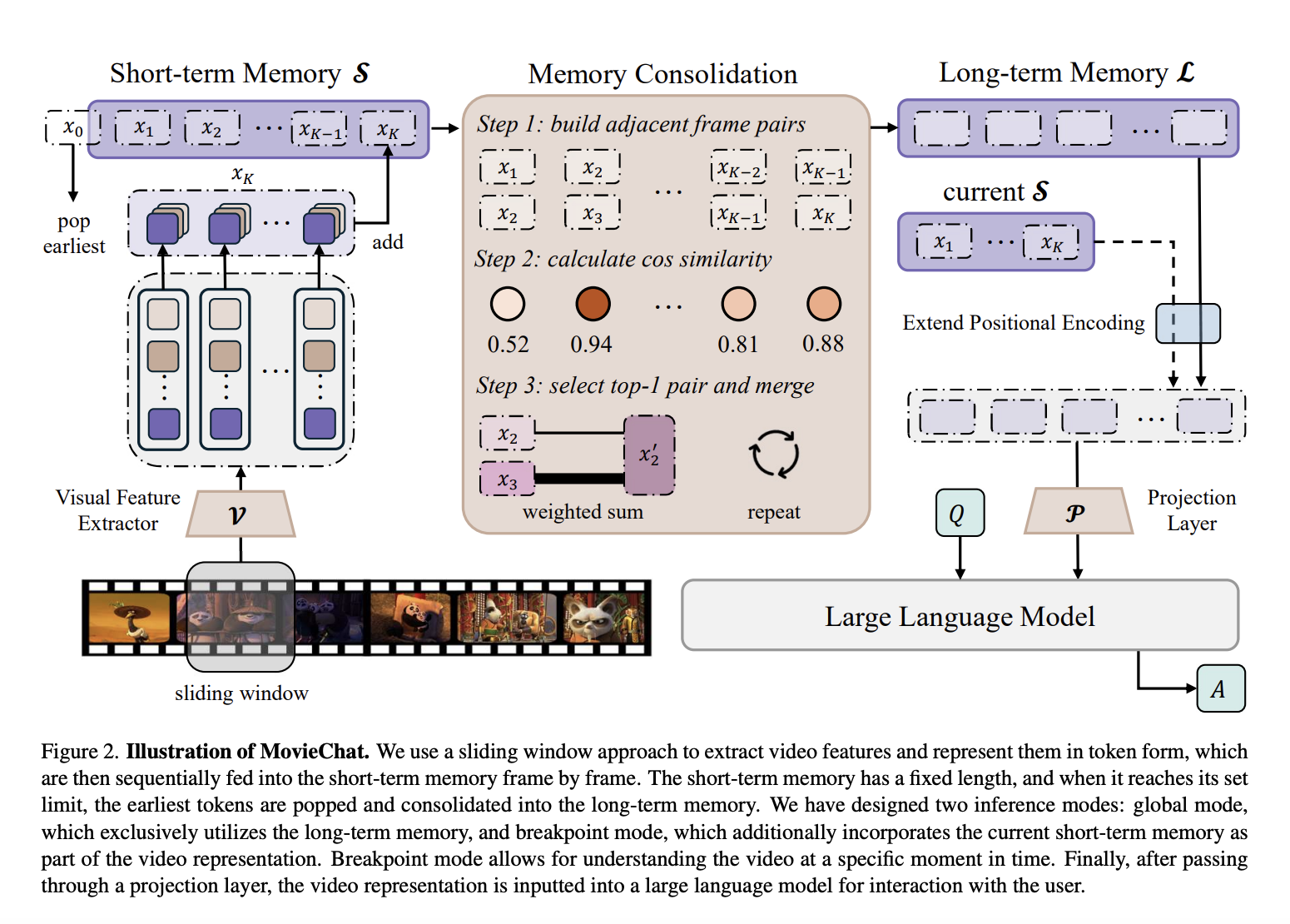
In this study researchers from Zhejiang University, University of Washington, Microsoft Research Asia, and Hong Kong University introduce MovieChat, a unique framework for lengthy video interpretation challenges that combines vision models with LLMs. According to them, the remaining difficulties for extended video comprehension include computing difficulty, memory expense, and long-term temporal linkage. To do this, they suggest a memory system based on the Atkinson-Shiffrin memory model, which entails a quickly updated short-term memory and a compact, long-lasting memory.
This unique framework combines vision models with LLMs and is the first to enable extended video comprehension tasks. This work is summarised as follows. They undertake rigorous quantitative assessments and case studies to assess the performance of both understanding capability and inference cost, and they offer a type of memory mechanism to minimize computing complexity and memory cost while improving the long-term temporal link. This research concludes by presenting a novel approach for comprehending videos that combine huge language models with video foundation models.
The system solves difficulties with analyzing lengthy films by including a memory process inspired by the Atkinson-Shiffrin model, consisting of short-term and long-term memory represented by tokens in Transformers. The suggested system, MovieChat, outperforms previous algorithms that can only process films containing a few frames by achieving state-of-the-art performance in extended video comprehension. This method addresses long-term temporal relationships while lowering memory use and computing complexity. The work highlights the role of memory processes in video comprehension, which allows the model to store and recall pertinent information for lengthy periods. The popularity of MovieChat has practical ramifications for industries, including content analysis, video recommendation systems, and video monitoring. Future studies might look into ways to strengthen the memory system and use additional modalities, including audio, to increase video comprehension. This study creates possibilities for applications needing a thorough comprehension of visual data. Their website has multiple demos.
Check out the Paper, GitHub, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.