This AI Research Introduces a Novel Two-Stage Pose Distillation for Whole-Body Pose Estimation
Numerous human-centric perception, comprehension, and creation tasks depend on whole-body pose estimation, including 3D whole-body mesh recovery, human-object interaction, and posture-conditioned human image and motion production. Furthermore, using user-friendly algorithms like OpenPose and MediaPipe, recording human postures for virtual content development and VR/AR has significantly increased in popularity. Although these tools are convenient, their performance still needs to improve, which limits their potential. Therefore, more developments in human pose assessment technologies are essential to realizing the promise of user-driven content production.
Comparatively speaking, whole-body pose estimation presents more difficulties than human pose estimation with body-only key points detection due to the following factors:
- The hierarchical structures of the human body for fine-grained key points localization.
- The small resolutions of the hand and face.
- The complex body parts match multiple people in an image, especially for occlusion and difficult hand poses.
- Data limitation, particularly for the whole-body images’ diverse hand pose and head pose.
Additionally, a model must be compressed into a thin network before deployment. Distillation, trimming, and quantization make up the fundamental compression techniques.
Knowledge distillation (KD) can boost a compact model’s effectiveness without adding unnecessary expenses to the inference process. This method, which has broad use in various tasks like categorization, detection, and segmentation, allows students to pick up knowledge from a more experienced teacher. A set of real-time pose estimators with good performance and efficiency are produced as a consequence of the investigation of KD for whole-body pose estimation in this work. Researchers from Tsinghua Shenzhen International Graduate School and International Digital Economy Academy specifically suggest a revolutionary two-stage pose distillation architecture called DWPose, which, as demonstrated in Fig. 1, provides cutting-edge performance. They use the most recent pose estimator, RTMPose, trained on COCO-WholeBody, as their fundamental model.
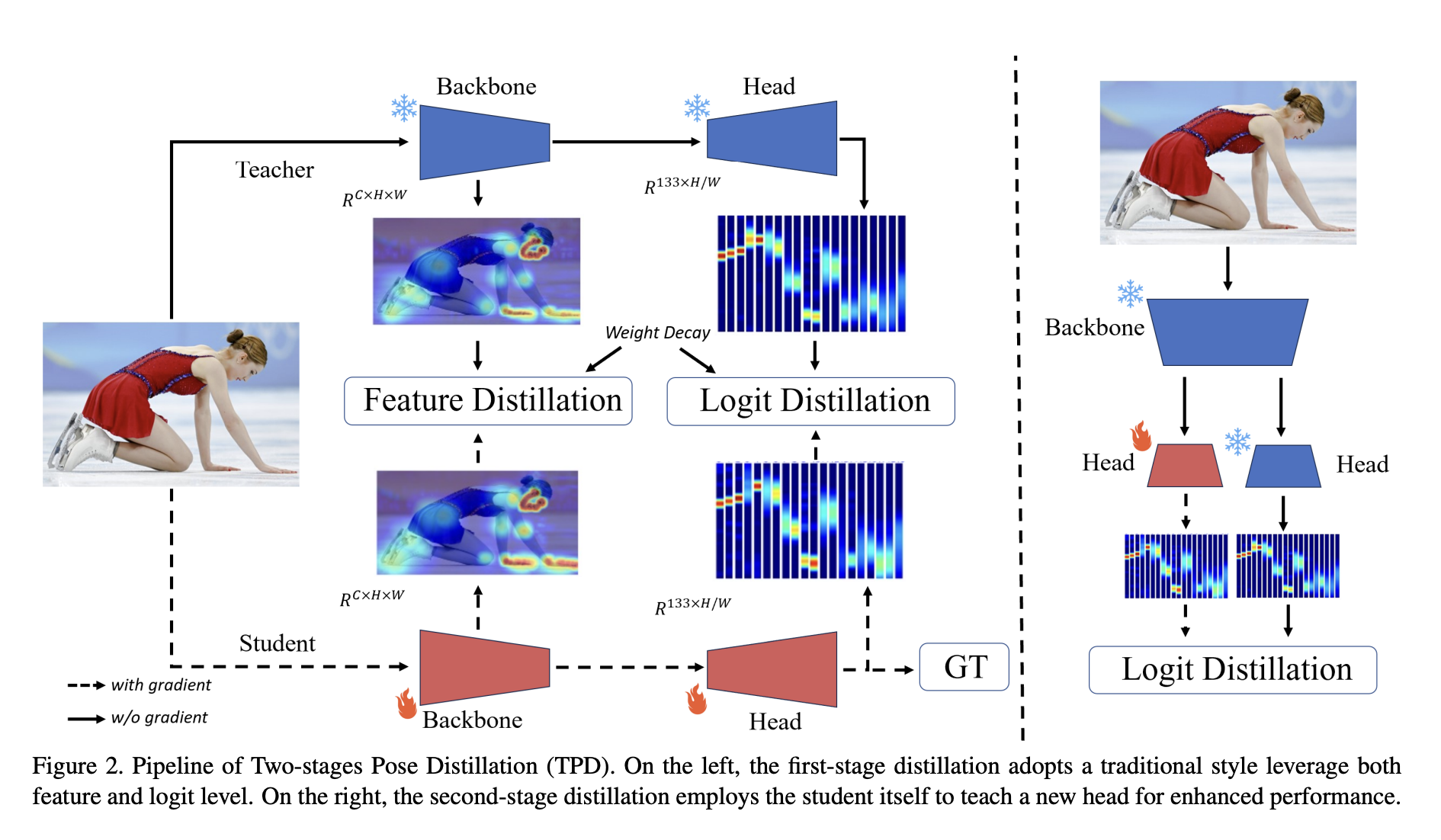
They natively use the teacher’s (e.g., RTMPose-x) intermediate layer and final logits in the first stage distillation to direct the student model (e.g., RTMPose-l). Keypoints may be distinguished in previous posture training by their visibility, and only visible key points are used for monitoring. Instead, they employ the teacher’s entire outputs which include both visible and invisible key points—as final logits, which may convey accurate and thorough values to aid in the learning process for the students. They also use a weight-decay approach to increase effectiveness, which progressively lowers the device’s weight throughout the training session. The second stage, distillation, suggests a head-aware self-KD to increase the capacity of the head since a better head would decide a more accurate localization.
They build two identical models, choosing one as the student to be updated and the other as the instructor. Only the head of the student is updated by the logit-based distillation, leaving the rest of the body frozen. Notably, this plug-and-play strategy works with dense prediction heads and enables the student to get better outcomes with 20% less training time, whether trained from the start with distillation or without. The volume and variety of data addressing different sizes of human body parts will impact the model’s performance. Due to the datasets ‘ need for comprehensive annotated key points, existing estimators must help accurately localize the fine-grained finger and facial landmarks.
Therefore, they incorporate an extra UBody dataset comprising numerous face and hand key points photographed in various real-life settings to examine the data effect. Thus, the following may be said about their contributions:
• To overcome the whole-body data limitation, they explore more comprehensive training data, especially on diverse and expressive hand gestures and facial expressions, making it applicable to real-life applications.
• They introduce a two-stage pose knowledge distillation method, pursuing efficient and precise whole-body pose estimation.
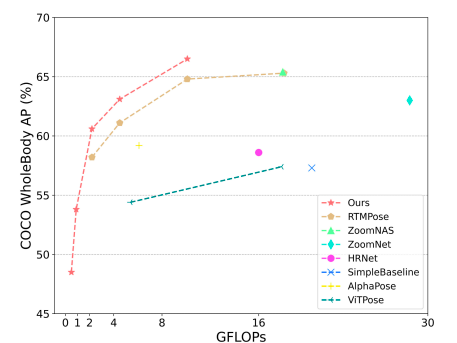
• Their suggested distillation and data techniques may greatly enhance RTMPose-l from 64.8% to 66.5% AP, even exceeding RTMPose-x instructor with 65.3% AP, using the most recent RTMPose as their base model. Additionally, they confirm DWPose’s strong efficacy and efficiency in generating work.
Check out the Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.