Can Large Language Models Help Long-term Action Anticipation from Videos? Meet AntGPT: An AI Framework to Incorporate Large Language Models for the Video-based Long-Term Action Anticipation Task
From video observations, research focuses on the LTA task—long-term action anticipation. Sequences of verb and noun predictions for an interested actor across a generally extended time horizon are its desired outcomes. LTA is essential for human-machine communication. A machine agent might use LTA to help people in situations like self-driving cars and routine domestic chores. Additionally, due to human behaviors’ inherent ambiguity and unpredictability, video action detection is quite difficult, even with perfect perception.
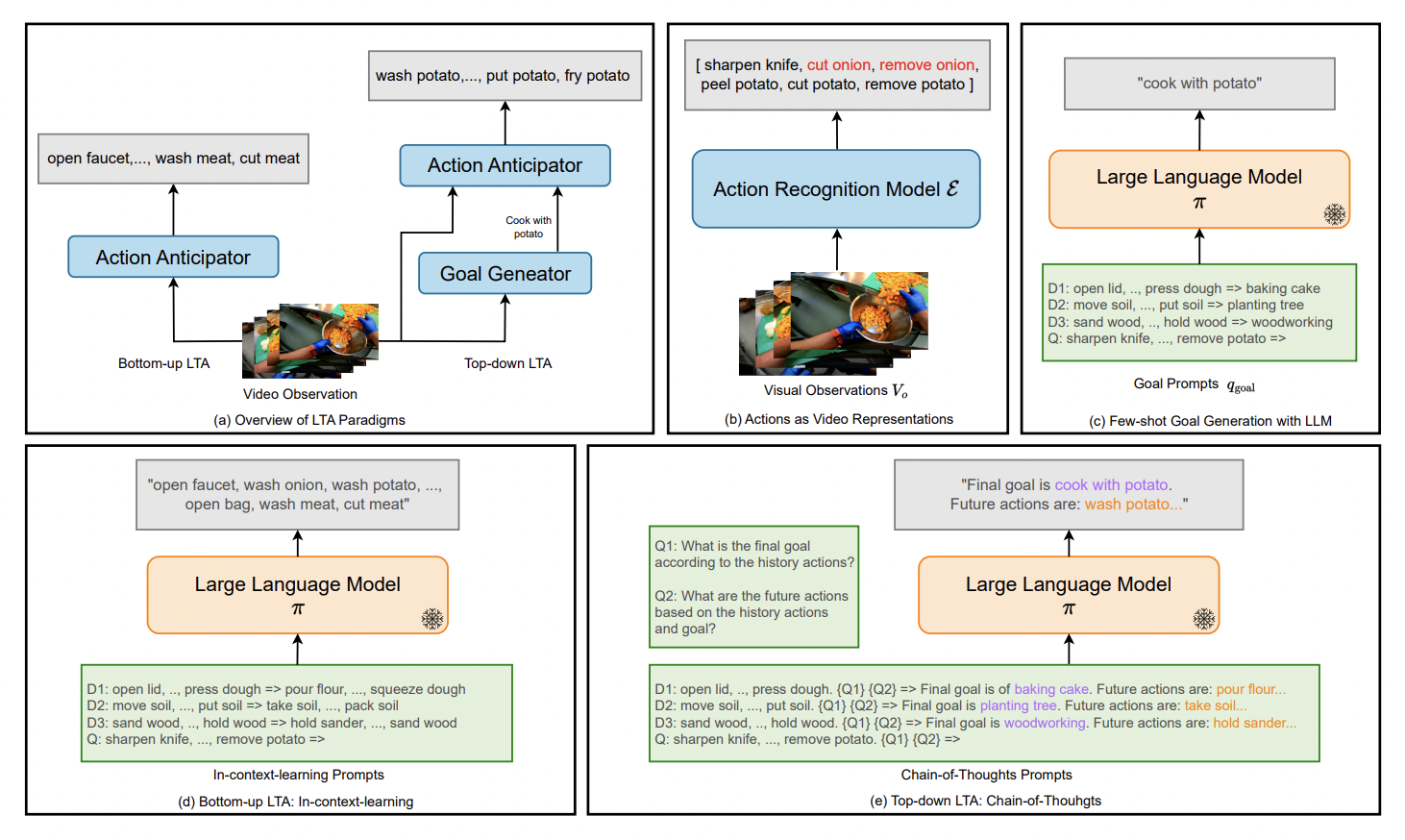
Bottom-up modeling, a popular LTA strategy, directly simulates human behavior’s temporal dynamics using latent visual representations or discrete action labels. Most current bottom-up LTA strategies are implemented as end-to-end trained neural networks using visual inputs. Knowing an actor’s goal may aid action prediction because human behavior, especially in everyday domestic situations, is frequently “purposive.” As a result, they consider a top-down framework in addition to the widely used bottom-up strategy. The top-down framework first outlines the process necessary to achieve the goal, thereby implying the longer-term aim of the human actor.
However, it is typically difficult to use goal-conditioned process planning for action anticipation since the target information is frequently left unlabeled and latent in current LTA standards. These issues are addressed in their study in both top-down and bottom-up LTA. They suggest examining whether large language models (LLMs) may profit from films because of their success in robotic planning and program-based visual question answering. They propose that the LLMs encode helpful prior information for the long-term action anticipation job by pretraining on procedural text material, such as recipes.
In an ideal scenario, prior knowledge encoded in LLMs can assist both bottom-up and top-down LTA approaches because they can respond to queries like, “What are the most likely actions following this current action?” as well as, “What is the actor trying to achieve, and what are the remaining steps to achieve the goal?” Their research specifically aims to answer four inquiries on using LLMs for long-term action anticipation: What is an appropriate interface for the LTA work between videos and LLMs, first? Second, are LLMs useful for top-down LTA, and can they infer the goals? Third, may action anticipation be aided by LLMs’ prior knowledge of temporal dynamics? Lastly, can they use the few-shot LTA functionality provided by LLMs’ in-context learning capability?
Researchers from Brown University and Honda Research Institute provide a two-stage system called AntGPT to do the quantitative and qualitative evaluations required to provide answers to these questions. AntGPT first identifies human activities using supervised action recognition algorithms. The OpenAI GPT models are fed the recognized actions by AntGPT as discretized video representations to determine the intended outcome of the actions or the actions to come, which may then optionally be post-processed into the final predictions. In bottom-up LTA, they explicitly ask the GPT model to predict future action sequences using autoregressive methods, fine-tuning, or in-context learning. They initially ask GPT to forecast the actor’s aim before producing the actor’s behaviors to accomplish top-down LTA.
They then use the goal information to provide predictions that are goal-conditioned. Additionally, they look at AntGPT’s capacity for top-down and bottom-up LTA using chains of reasoning and few-shot bottom-up LTA, respectively. They do tests on several LTA benchmarks, including EGTEA GAZE+, EPIC-Kitchens-55, and Ego4D. The quantitative tests demonstrate the viability of their suggested AntGPT. Additional quantitative and qualitative studies show that LLMs can infer the actors’ high-level objectives given discretized action labels from the video observations. Additionally, they note that the LLMs can execute counterfactual action anticipation when given a variety of input objectives.
Their study contributes the following:
1. They suggest using big language models to infer objectives model temporal dynamics and define long-term action anticipation as bottom-up and top-down methods.
2. They suggest the AntGPT framework, which naturally connects LLMs with computer vision algorithms for comprehending videos and achieves state-of-the-art long-term action prediction performance on the EPIC-Kitchens-55, EGTEA GAZE+, and Ego4D LTA v1 and v2 benchmarks.
3. They carry out comprehensive quantitative and qualitative assessments to comprehend LLMs’ crucial design decisions, benefits, and drawbacks when used for the LTA job. They also plan to release the code soon.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.