Top BERT Applications You Should Know About
Language model pretraining has significantly advanced the field of Natural Language Processing (NLP) and Natural Language Understanding (NLU). It has been able to successfully improve the performance of various NLP tasks, such as sentiment analysis, question answering, natural language inference, named entity recognition, and textual similarity. Models like GPT, BERT, and PaLM are getting popular for all the good reasons. They imitate humans by generating accurate content, answering questions, summarizing textual paragraphs, translating languages, and so on. The well-known model BERT, which stands for Bidirectional Encoder Representations from Transformers, has a number of amazing applications.
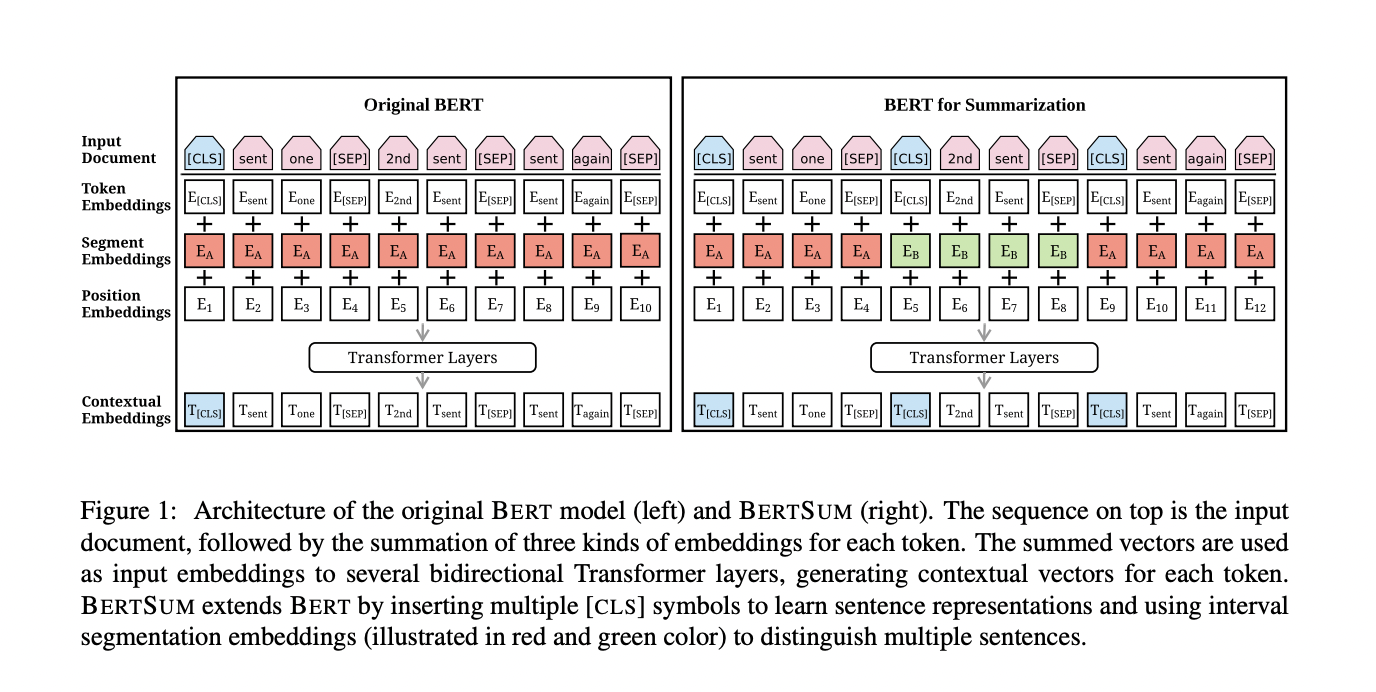
BERTSUM
Text summarization necessitates a deeper comprehension of language than just words and sentences. It aims to reduce a document to a manageable length while keeping the majority of its meaning. Two basic paradigms that can be used to summarise text are extractive and abstractive. When extractive summarization is used, the task is approached as a binary classification issue, and the model determines whether or not to include a certain sentence in the summary. On the other hand, abstractive summarization uses language-generating tools to provide summaries containing original words and phrases that aren’t found in the source text.
Recent research investigates the potential of BERT for text summarization. The team has suggested a unique BERT-based document-level encoder that can represent both the complete document and its component phrases in order to achieve this. To capture document-level information for sentence extraction in the extractive model, they have stacked numerous inter-sentence Transformer layers on top of this encoder. The same pretrained BERT encoder and a Transformer decoder with a random initialization are combined in the abstractive model.
Google Smart Search
The latest research has used BERT to improve Google search results for a specific query. Previously, a search for “2019 Brazil traveler to the USA need a visa” would have turned up information about American residents visiting Brazil. On the other hand, BERT enables the search engine to understand the question more precisely and identify the user as a Brazilian traveler looking for information about visa requirements for entering the USA. As a result, the user will find the search results to be more useful and relevant.
The integration of BERT into the search engine also has a positive impact on featured snippets, which are the condensed summaries of data that appear at the top of search results and succinctly respond to a user’s query. A better contextual understanding of queries, thanks to BERT, results in more accurate highlighted snippets and, ultimately, a better user experience. BERT does not take the role of Google’s established ranking formulas. Instead, it acts as an additional tool to help search engines more fully comprehend the context and meaning of search queries, allowing them to present results that are more pertinent and aware of their context.
SciBERT
A team of researchers from the Allen Institute for Artificial Intelligence, Seattle, WA, USA, have proposed SCIBERT, which is a unique resource created to improve performance on a variety of NLP tasks in the scientific domain. It is based on BERT and has been developed using a sizable corpus of scientific material. The idea is to modify BERT in order to help it comprehend and deal with the particular language and vocabulary used in scientific writing.
The purpose of this study was to investigate the performance of task-specific architectures with frozen embeddings versus finetuning. The authors have examined SciBERT on a variety of tasks in the scientific field, and on many of these tasks, they obtained new state-of-the-art results. This demonstrates how SCIBERT works to enhance performance and comprehension of scientific language in different NLP applications.
BioBERT
As the volume of biomedical documents increases quickly, the field of biomedical text mining has become more and more important. Deep learning has been essential in creating efficient biomedical text-mining models. In recent research, the team has focussed on how BERT can be modified for use with biological corpora. They have suggested BioBERT (Bidirectional Encoder Representations from Transformers for Biomedical Text Mining) as a solution to this drawback. A domain-specific language representation model called BioBERT has been pre-trained using sizable biomedical corpora.
BERT will be adjusted to work better with biomedical texts in order to undertake tasks involving biomedical text mining. While BERT performs comparably to previous state-of-the-art models, BioBERT has significantly surpassed them in three representative biomedical text mining tasks – Biomedical Named Entity Recognition, Biomedical Relation Extraction, and Biomedical Question Answering.
ClinicalBERT
Clinical notes are the ones that include useful patient information that isn’t contained in structured data, including test results or prescription information. Since they are scarce and high-dimensional, drawing out significant patterns and relationships from them is challenging. A team of researchers has parsed clinical text using BERT to do this. Although clinical text differs greatly from typical corpora like Wikipedia and BookCorpus, publicly available BERT parameters were trained on these sources. The team has pre-trained BERT using clinical notes to successfully adapt it to the unique features of medical language in order to address this issue.
A model known as ClinicalBERT is the end result of this process of adaptation and finetuning. This model is a useful resource for comprehending clinical writing because it identifies correlations between medical concepts that are of a high caliber as judged by medical professionals. When predicting 30-day hospital readmission using both discharge reports and the first few days of critical care unit notes, ClinicalBERT outperforms a number of baselines. The model performs better than expected on a number of clinically relevant evaluation parameters.
In conclusion, the popular Large Language Model called BERT has plenty of applications that can be utilized and offer a fresh perspective for various time-consuming tasks.
This Article is based on this Tweet thread. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.