Meet Retroformer: An Elegant AI Framework for Iteratively Improving Large Language Agents by Learning a Plug-in Retrospective Model
A potent new trend has emerged in which large language models (LLMs) are enhanced to become autonomous language agents capable of carrying out activities independently, eventually in the service of a goal, instead of merely responding to user questions. React, Toolformer, HuggingGPT, generative agents, WebGPT, AutoGPT, BabyAGI, and Langchain are some of the well-known research that has effectively demonstrated the practicality of developing autonomous decision-making agents by utilizing LLMs. These methods use LLMs to produce text-based outputs and actions that can then be used to access APIs and carry out activities in a specific context.
The majority of present language agents, however, do not have behaviors that are optimized or in line with environment reward functions because of the enormous scope of LLMs with a high parameter count. Reflexion, a fairly recent language agent architecture, and many other works in the same vein, including Self-Refine and Generative Agent, are an anomaly because they employ verbal feedback—specifically, self-reflection—to assist agents in learning from past failures. These reflecting agents convert the environment’s binary or scalar rewards into vocal input as a textual summary, providing further context to the language agent’s prompt.
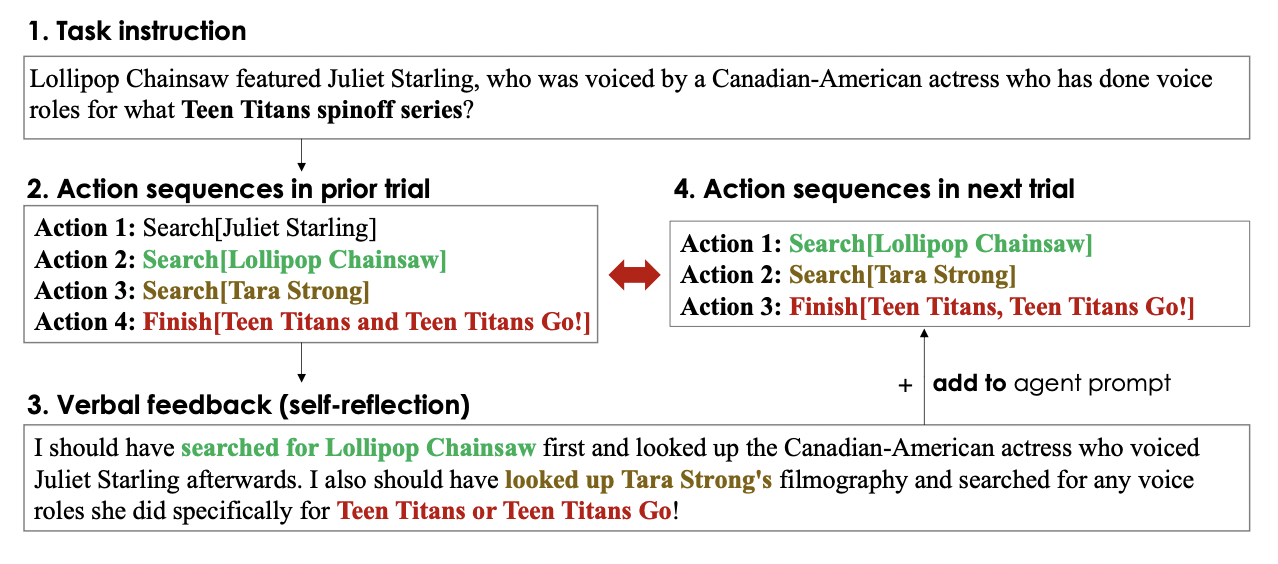
The self-reflection feedback serves as a semantic signal for the agent by giving it a specific area to focus on for improvement. This enables the agent to learn from past failures and avoid repeating the same mistakes repeatedly so that it may do better on the next try. Although iterative refinement is made possible by the self-reflection operation, it can be difficult to generate useful reflective feedback from a pre-trained, frozen LLM, as shown in Fig. 1. This is because the LLM must be able to identify the areas in which the agent erred in a particular environment, such as the credit assignment problem, and produce a summary with suggestions for how to improve.
The frozen language model needs to be sufficiently tweaked to specialize in credit assignment issues for the tasks in particular circumstances to optimize verbal reinforcement. Additionally, present language agents do not reason or plan in ways consistent with differentiable, gradient-based learning from rewards by using the numerous reinforcement learning approaches now in use. Researchers from Salesforce Research introduce Retroformer, a moral framework for reinforcing language agents by learning a plug-in retrospective model to solve constraints. Retroformer automatically improves language agent prompts based on input from the environment through policy optimization.
In particular, the proposed agent architecture can iteratively refine a pre-trained language model by reflecting on failed attempts and allocating credits for actions taken by the agent on future rewards. This is done by learning from arbitrary reward information across multiple environments and tasks. They undertake experiments on open-source simulation and real-world settings, such as HotPotQA, to evaluate the tool usage skills of a web agent who must contact Wikipedia APIs repeatedly to answer questions. HotPotQA comprises search-based question-answering tasks. Retroformer agents, in contrast to reflection, which does not employ gradient for thinking and planning, are faster learners and better decision-makers. More specifically, Retroformer agents increase the HotPotQA success rate of search-based question-answering tasks by 18% in just four tries, proving the value of gradient-based planning and reasoning for tool usage in environments with a lot of state-action space.
In conclusion, the following is what they have contributed:
• The research develops Retroformer, which improves learning speed and task completion by repeatedly refining the prompts supplied to big language agents based on contextual input. The proposed method focuses on enhancing the retrospective model in the language agent architecture without accessing the Actor LLM parameters or needing to propagate gradients.
• The proposed method allows learning from various reward signals for diverse tasks and environments. Retroformer is an adaptable plug-in module for many kinds of cloud-based LLMs, such as GPT or Bard, because of its agnostic nature.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.