A New AI Research from China Introduces RecycleGPT: A Generative Language Model with a Fast Decoding Speed of 1.4x by Recycling Pre-Generated Model States without Running the Whole Model in Multiple Steps
When creating satisfactory text across a wide range of application areas, large language models (LLMs) have been a game-changer in natural language production. While scaling to bigger models (100B+ parameters) considerably improves performance, the reality remains that the time required to complete a single decoding step grows with model size. Greater models introduce massive computation and have a greater memory footprint, both of which contribute significantly to the slow inference of LLMs. The memory requirements for the KV cache and the trained model parameters and the temporary state needed for inference are substantial.
Token generation in LLMs is slow because of the system’s slow memory access speed. As for the time required to produce each token, it roughly correlates to the total number of model parameters.
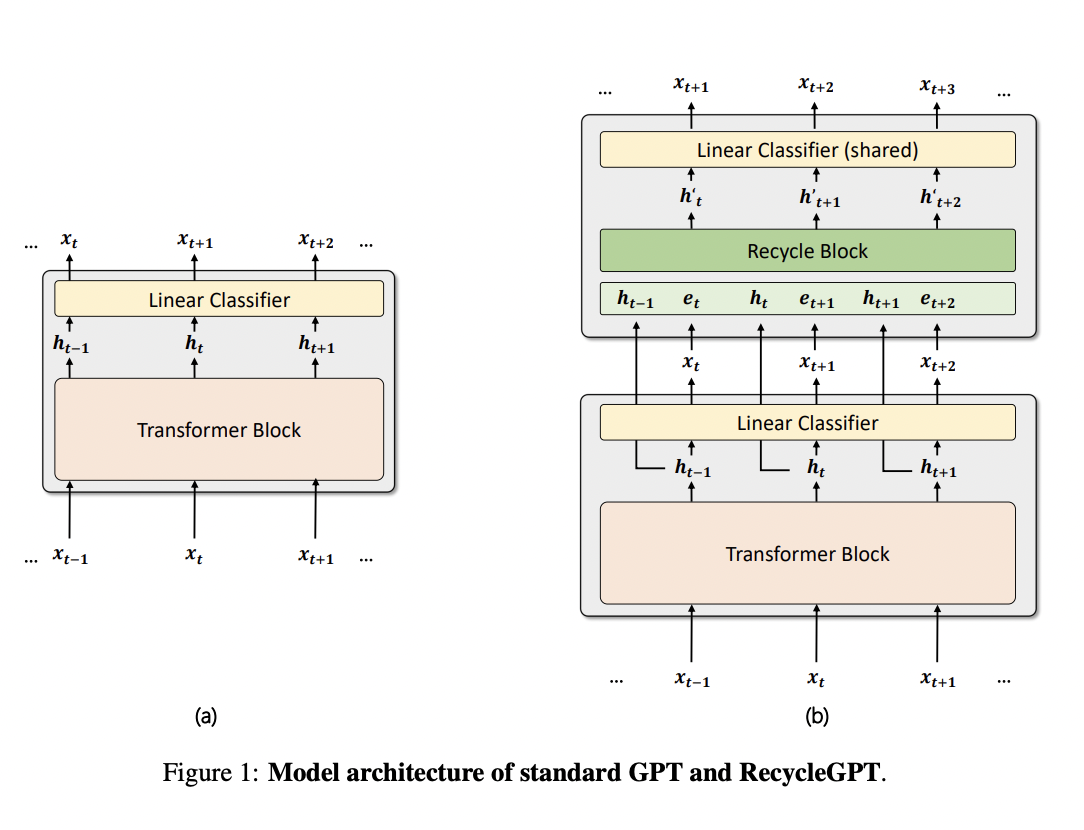
Several works are offered to make inference more effective. The fundamental focus of these studies is on minimizing memory usage and relieving memory traffic congestion. A new study by the National Supercomputing Center in Wuxi and Tsinghua University investigates efficient decoding techniques to maximize token generation while keeping the memory processing budget constant. To achieve rapid decoding, they introduce a new language model architecture called RecycleGPT, which can reuse previously created model states.
Their strategy involves tweaking the original language model by incorporating a new recyclable module that predicts the next few tokens based on previously generated states without repeatedly running the complete model. The recyclable module is built from several transformer-based layers, which together allow for better representations to be made when making predictions. RecycleGPT can be combined with the conventional decoding technique in several different ways for usage during inference. This study employs them cyclically (i.e., producing every two tokens involves running the whole model once), leaving the investigation of other ways for future research. The purpose of the recyclable module was to speed up the decoding process, and it was able to do this because, despite its simplistic architecture, the module could efficiently represent contextual information and generate correct predictions.
The team put the RecycleGPT through its paces against several industry norms. The findings show that the model is 1.4 times faster than state-of-the-art language models with only 15% more parameters while maintaining similar performance on downstream tasks. The researchers plan to present different-sized models of RecycleGPT shortly.
Because of its adaptability and scalability, our recycling technique can be used with various pre-trained models. In addition, the creation technique and the size of the recyclable modules can be modified to reach the necessary speed-up performance.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.