Meet AgentBench: A Multidimensional Benchmark Which Has Been Developed To Assess Large Language Models-As-Agents In A Variety Of Settings
Large Language Models (LLMs) have emerged and advanced, adding a new level of complexity to the field of Artificial Intelligence. Through intensive training methods, these models have mastered some amazing Natural Language Processing, Natural Language Understanding, and Natural Language Generation tasks such as answering questions, comprehending natural language inference, and summarising material. They have also accomplished activities that are not commonly associated with NLP, such as grasping human intent and executing instructions.
Applications like AutoGPT, BabyAGI, and AgentGPT, which use LLMs to achieve autonomous goals, have been made possible thanks to all NLP advancements. Though these approaches have generated a lot of interest from the public, the absence of a standardized baseline for assessing LLMs-as-Agents continues to be a significant obstacle. Although text-based game environments have been used in the past to evaluate language agents, they frequently have drawbacks due to their confined and discrete action spaces. Also, they primarily evaluate models’ capacities for commonsense grounding.
Most existing benchmarks for agents focus on a particular environment, which limits their ability to give a thorough assessment of LLMs across various application contexts. To address these issues, a team of researchers from Tsinghua University, Ohio State University, and UC Berkeley has introduced AgentBench, which is a multidimensional benchmark created to assess LLMs-as-Agents in a variety of settings.
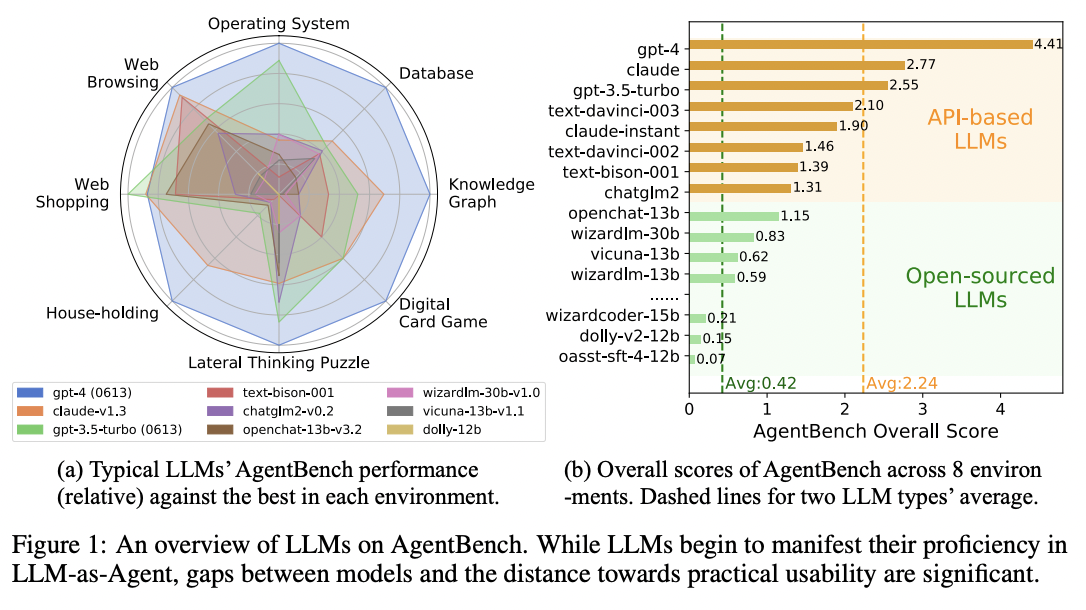
Eight different settings are included in AgentBench, five of which are brand-new: lateral thinking puzzles (LTP), knowledge graphs (KG), digital card games (DCG), operating systems (OS), databases (DB), and knowledge graphs. The final three environments—housekeeping (Alfworld), online shopping (WebShop), and web browsing (Mind2Web)—are adapted from pre-existing datasets. These environments have all been thoughtfully designed to represent interactive situations in which text-based LLMs can act as autonomous agents. They rigorously assess key LLM skills like coding, knowledge acquisition, logical reasoning, and following directions, as a result of which AgentBench serves as a thorough testbed for assessing both agents and LLMs.
Using AgentBench, the researchers have thoroughly analyzed and evaluated 25 distinct LLMs, including API-based and open-source models. The findings have shown that top-tier models like GPT-4 are adept at managing a wide range of real-world tasks, suggesting the possibility of creating highly competent and constantly adapting agents. However, these top API-based models perform noticeably worse than their open-source equivalents. Open-source LLMs perform well in other benchmarks, but when AgentBench’s difficult tasks are presented to them, they suffer a lot. This emphasizes the need for additional initiatives to improve the open-source LLMs’ capacity for learning.
The contributions can be summarized as follows –
- AgentBench is a thorough benchmark that defines standardized evaluation procedures and introduces the innovative concept of evaluating LLMs as agents. It provides a useful platform for evaluating the various capacities of LLMs by integrating eight authentic environments that simulate real-world circumstances.
- The study thoroughly evaluates 25 different LLMs using AgentBench, revealing a significant performance gap between leading commercial API-based LLMs and open-source alternatives. This assessment highlights LLM-as-Agent’s current condition and identifies areas that could use improvement.
- The study also provides an integrated toolset based on the ‘API & Docker’ interaction paradigm that makes it easier to customize the AgentBench assessment procedure. The availability of this toolset for the larger research community, coupled with pertinent datasets and environments, promotes cooperative research and development in the field of LLMs.
Check out the Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.