Google AI Introduces AdaTape: A New AI Approach with a Transformer-based Architecture that Allows for Dynamic Computation in Neural Networks through Adaptive Tape Tokens
While humans possess the ability to adapt their thinking and responses based on varying situations or conditions, Neural Networks, though incredibly potent and intricately designed, are constrained by fixed functions and inputs. They consistently execute the same function regardless of the nature or intricacy of the presented samples.
To address this issue, the researchers use adaptivity (a powerful paradigm as it not only imbues practitioners with flexibility pertaining to the downstream usage of these models but can also serve as a powerful inductive bias for solving certain challenging classes of problems). It refers to the ability of a machine learning system to adjust its behavior in response to the change in the scenario or environment.
While conventional neural networks have a fixed function and computation capacity, a model with adaptive and dynamic computation modulates the computational budget it dedicates to processing each input, depending on the complexity of the input. Adaptive computation in neural networks is appealing for two reasons. One, they provide an inductive bias that enables different numbers of computational steps for different inputs, which can be crucial in solving arithmetic problems requiring modeling hierarchies of different depths. Second, it facilitates the ability to tune the cost of inference through greater flexibility offered by dynamic computation, as these models can be adjusted to spend more FLOPs processing a new input.
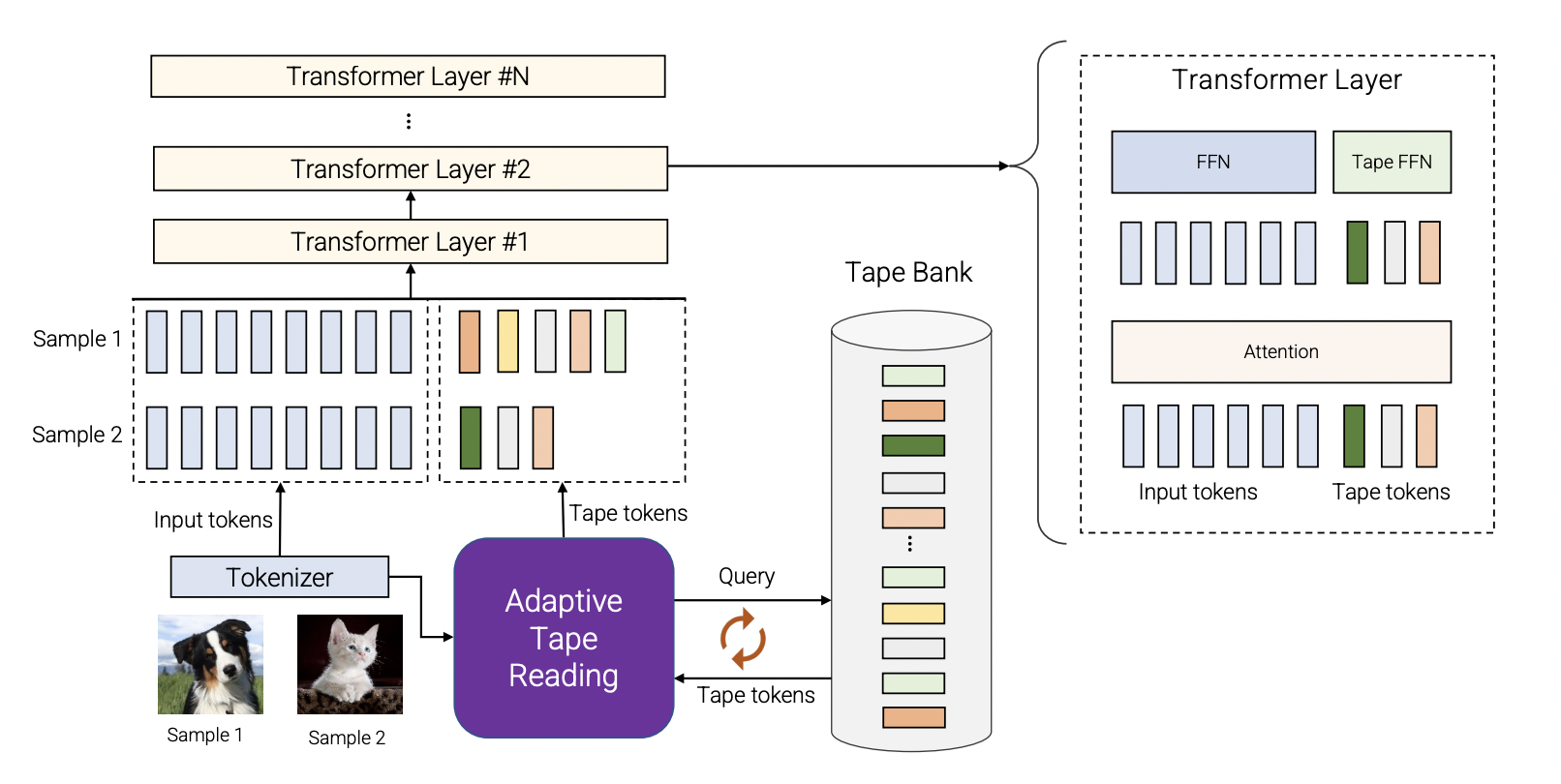
Consequently, the researchers of Google have introduced a new model that utilizes adaptive computation, called AdaTape. AdaTape is very simple to implement as it directly injects adaptivity into the input sequence instead of the model depth and is also very accurate. AdaTape uses an adaptive tape reading mechanism to determine various tape tokens added to each input based on the input’s complexity.
AdaTape is a Transformer-based architecture that uses a dynamic set of tokens to create an elastic input sequence. AdaTape uses the adaptive function. Also, it uses a vector representation to represent each input to select a variable-sized sequence of tape tokens dynamically.
AdaTape uses a “ tape bank” to store all the candidate tape tokens that interact with the model through the adaptive tape reading mechanism to make a dynamic selection of a variable-size sequence of tape tokens. The researchers used two different methods for creating the tape bank: an input-driven bank(the input-driven bank extracts a bank of tokens from the input while employing a different approach than the original model tokenizer for mapping the raw input to a sequence of input tokens) and a learnable bank(a more general method for generating the tape bank by using a set of trainable vectors as tape tokens).
After this, the tape tokens are appended with the original input and sent to the transformer. Then, the two feed-forward networks are used. One is used for original input, and the other for all tape tokens. The researchers observed slightly better quality using separate feed-forward networks for input and tape tokens.
The researchers tested the utility of AdaTape on many parameters. They found that it outperforms all baselines incorporating recurrence within its input selection mechanism, providing an inductive bias that enables the implicit maintenance of a counter, which is impossible in standard Transformers. The researchers also evaluated AdaTape on image classification tasks. They tested AdaTape on ImageNet-1K and found that in terms of quality and cost tradeoff, AdaTape performs much better than the alternative adaptive transformer baselines.
Check out the Paper and Google Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.