Comparing Machine Learning Methods: Traditional vs. Cost-saving Alternatives – What Really Works?
Artificial Intelligence is tremendously increasing daily in various profiles like Cloud platforms, finance, quantitative finance, product design, and many more. Many researchers are still working on the role of Human chatbots and the application of machine-learning techniques in developing these chatbot models. Implementing a chatbot model, Training it, and Testing it requires huge data and cost implementation. This comes under a broad category of Natural Language Processing as well as Computer Vision. To solve this crisis of the economy, Researchers at the University College London and the University of Edinburgh are working on Machine Learning techniques to build a better model to solve this crisis.
The researchers are still working to solve these problems related to the economy of cloud platforms like AWS. The team of research scientists developed a Machine Learning approach which was based on the measurement system. There was a comparison between the normal Machine Learning models as well as the new model developed via Machine learning. This resulted in a cost-saving approach, which was quite good but also had some disadvantages. These cost-saving models predicted the minimal or the least possible results. The solution of problem statement was further solved by the researchers dividing it into three main categories.
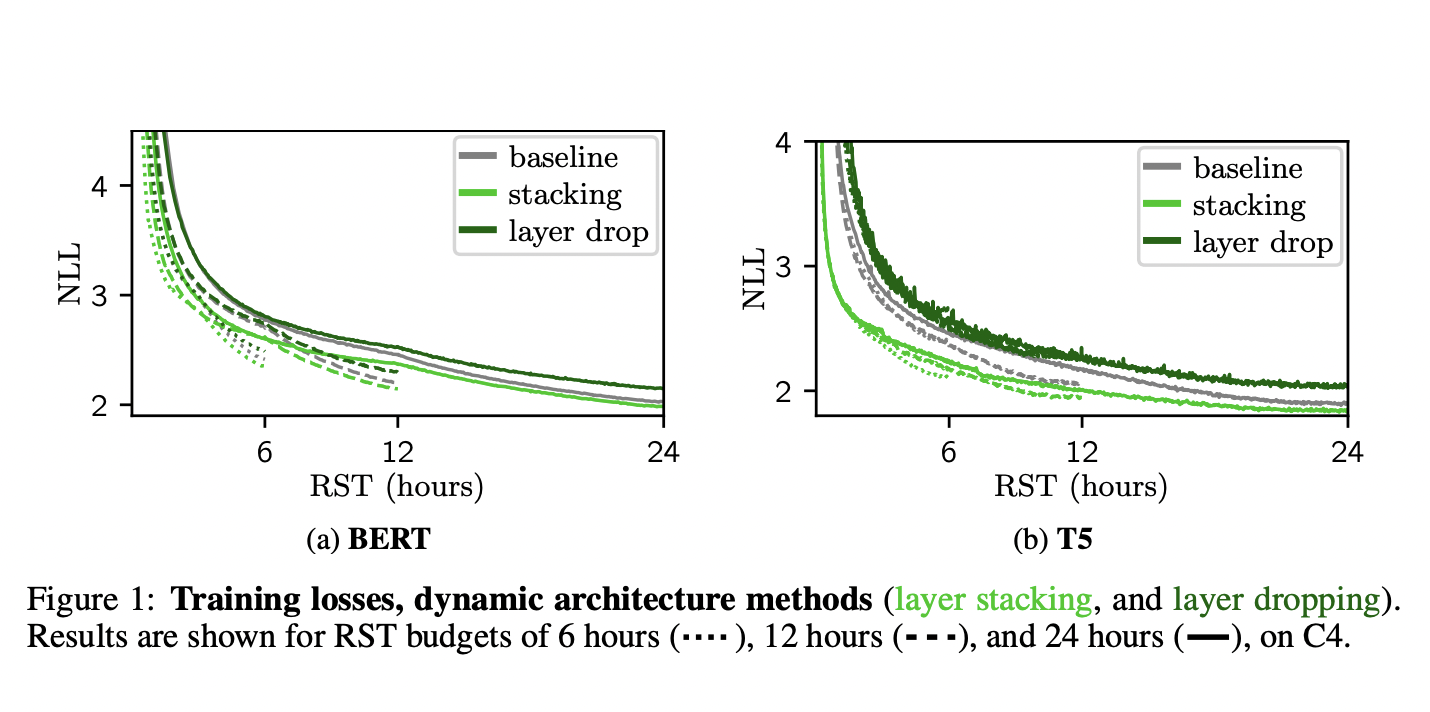
The researchers implemented batch selection as its first approach. This involves an extensive large number of images stacked together. These were arranged one by one orderly in a specific pattern. Batch Selection was one of the cheaper approaches used to date but still has some deficits. The second approach that researchers used is called Layer Stacking. This involves multiple neural networks stacked together. This model uses stacking to implement the model. Sentiment Analysis also plays a major role in the Layer Stacking process. The third approach designed by the researchers was based on efficient optimizers. This approach was based on making minimal wasteful things and also accelerates the search function. This approach was the most optimum as it provided solutions with excellent accuracy. Optimizers that were used in the process were twice as fast as the Adam Optimizer.
Using all the data simultaneously and leaving the gangue information doesn’t allow proper output to be generated. Out of all three outputs, layer stacking was the only approach that involved minimal validation and training gains. Such processes are improving on a large scale nowadays. Many researchers are working on the same process. The researchers developed an optimization technique that used less computing power than before. The overall result of ‘No train, no gain’ was passed after the research project was completed.
Check out the Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Bhoumik Mhatre is a Third year UG student at IIT Kharagpur pursuing B.tech + M.Tech program in Mining Engineering and minor in economics. He is a Data Enthusiast. He is currently possessing a research internship at National University of Singapore. He is also a partner at Digiaxx Company. ‘I am fascinated about the recent developments in the field of Data Science and would like to research about them.’
Credit: Source link
Comments are closed.