Researchers from ByteDance and CMU Introduce AvatarVerse: A Novel AI Pipeline for Generating High-Quality 3D Avatars Controlled by both Text Descriptions and Pose Guidance
3D avatars have extensive use in industries including game development, social media and communication, augmented and virtual reality, and human-computer interaction. The construction of high-quality 3D avatars has attracted a lot of interest. These complex 3D models are traditionally built manually, which is a labor-intensive and time-consuming procedure that takes thousands of hours from trained artists with substantial aesthetic and 3D modeling knowledge. As a result, their work’s objective is to automate the creation of high-quality 3D avatars using solely natural language descriptions because this has significant research potential and the ability to conserve resources.
Reconstructing high-fidelity 3D avatars from multi-view films or reference photos has garnered much attention recently. These techniques cannot construct imaginative avatars with complicated text prompts since they rely on restrictive visual priors obtained from films or reference pictures. Diffusion models display impressive ingenuity when creating 2D images, mostly because many large-scale text-image combinations are available. However, the lack of diversity and shortage of 3D models make it difficult to train a 3D diffusion model adequately.
Recent research has looked into optimizing Neural Radiance Fields for producing high-fidelity 3D models using pre-trained text-image generative models. However, creating solid 3D avatars with various positions, looks, and forms are still challenging. For instance, using common score distillation sampling without extra control to direct NeRF optimization will likely introduce the Janus issue. Aside from that, the avatars created by the present methods frequently display observable coarseness and blurriness, which results in the absence of high-resolution local texture details, accessories, and other important aspects.
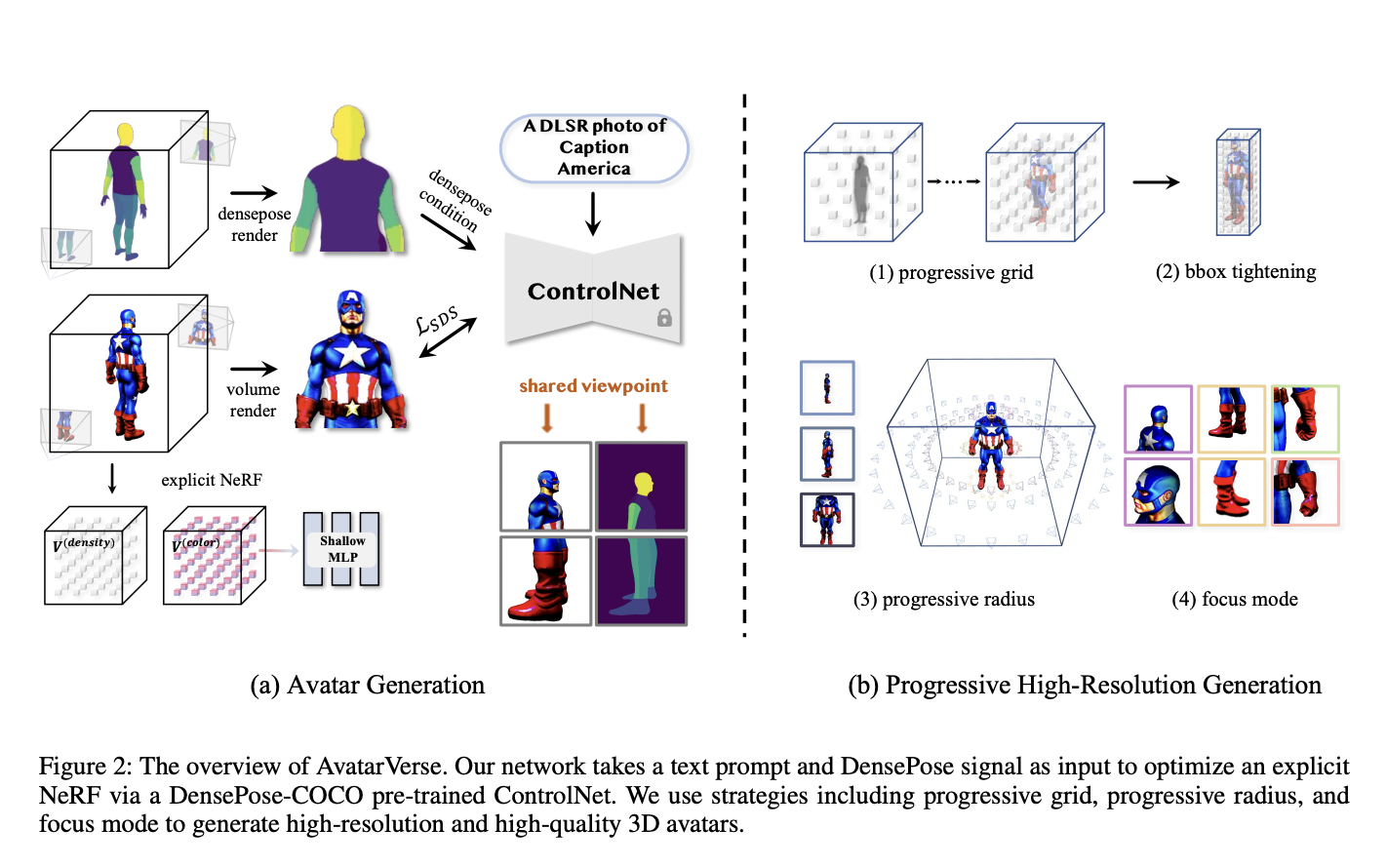
Researchers from ByteDance and CMU suggest AvatarVerse, a unique framework made for producing high-quality and reliable 3D avatars using textual descriptions and position guidances, to address these limitations. They initially train a brand-new ControlNet using 800K or more human DensePose pictures. Then, on top of the ControlNet, SDS loss conditional on the 2D DensePose signal is implemented. They can achieve exact view correspondence between every 2D view and the 3D space and between many 2D views. Their technology does away with the Janus problem that plagues the majority of previous approaches while also enabling pose control of the created avatars. As a result, it guarantees a more reliable and consistent generation procedure for avatars. The produced avatars may also be well aligned with the joints of the SMPL model thanks to the precise and adaptable supervision signals offered by DensePose, making skeletal binding and control easy and efficient.
They present a progressive high-resolution generation technique to improve the realism and detail of local geometry, whereas just relying on DensePose-conditioned ControlNet may produce local artifacts. They use a smoothness loss, which regularises the synthesis process by promoting a smoother gradient of the density voxel grid within their computationally effective explicit Neural Radiance Fields to reduce the coarseness of the created avatar.
These are the overall contributions:
• They introduce AvatarVerse, a technique that allows a high-quality 3D avatar to be automatically created using only a word description and a reference human stance.
• They provide the DensePose-Conditioned Score Distillation Sampling Loss, a method that makes it easier to create pose-aware 3D avatars and successfully mitigates the Janus problem, improving system stability.
• Through a methodical high-resolution generating process, they improve the quality of the generated 3D avatars. This technology creates 3D avatars with exceptional detail, including hands, accessories, and more, through a rigorous coarse-to-fine refinement process.
• AvatarVerse performs admirably, outperforming competitors in quality and stability. AvatarVerse’s superiority in creating high-fidelity 3D avatars is demonstrated by meticulous qualitative assessments supported by thorough user research.
This sets a new standard for reliable, zero-shot 3D avatar generation of the highest caliber. They have put up demos of their technique on their GitHub website.
Check out the Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.