Meta AI’s Humpback! Making a Splash with Self-Alignment of LLMs with Instruction Backtranslation
Large Language Models (LLMs) have shown excellent generalization capabilities such as in-context-learning and chain-of-thoughts reasoning. To enable LLMs to follow natural language instructions and complete real-world tasks, researchers have been exploring methods of instruction-tuning of LLMs. This is implemented by fine-tuning the model on various functions using human-annotated prompts and feedback or supervised finetuning using public benchmarks and datasets augmented with manually or automatically generated instructions. Recent research emphasises the significance of human-annotation data quality. However, it has been discovered that annotating instructions following datasets with such quality is difficult to scale.
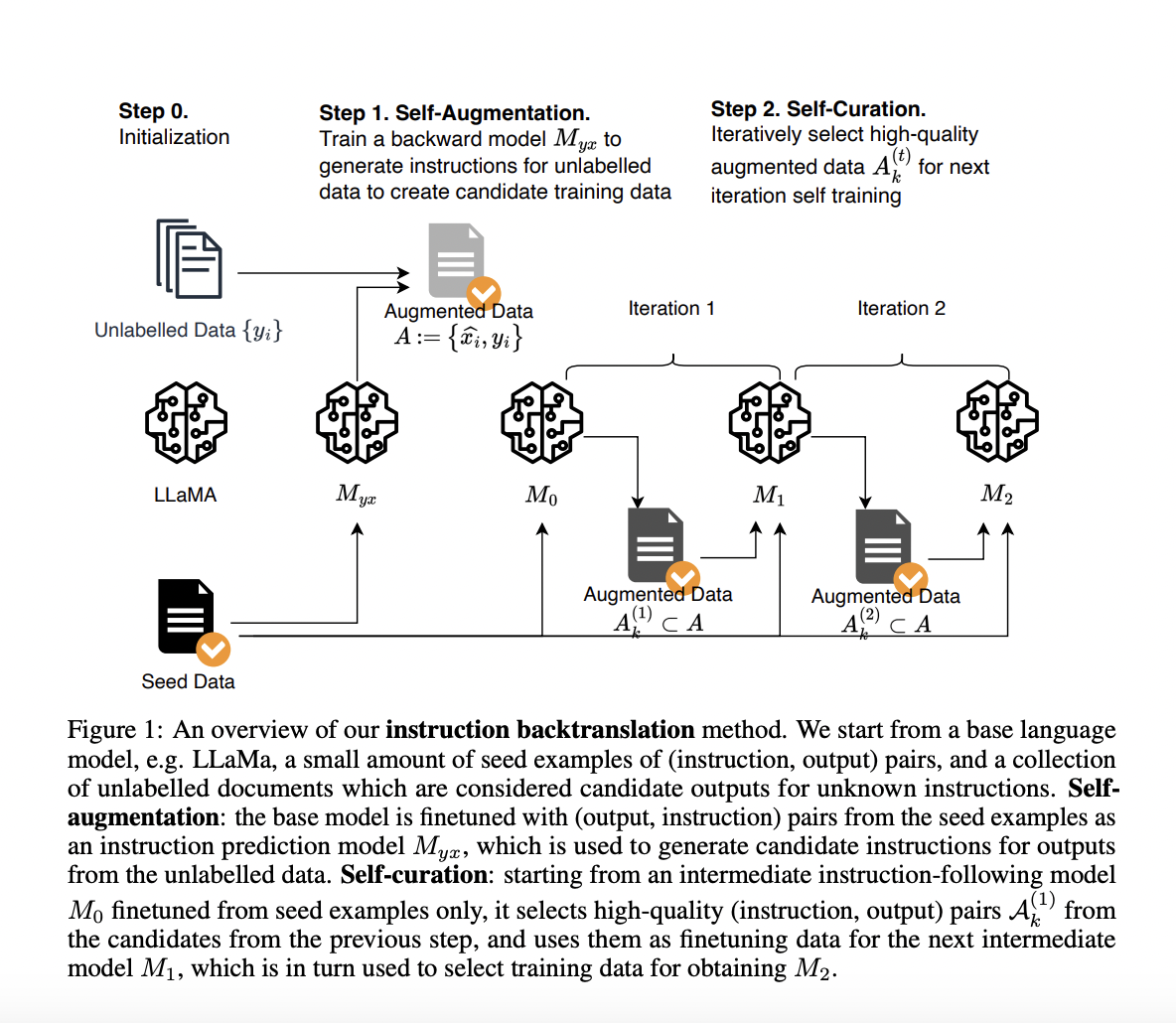
This solution deals with self-alignment with LLM, i.e., utilizing the model to improve itself and align its response with desired behaviours such as model-written feedback, critique, explanations, etc. Researchers at Meta AI have introduced Self Alignment with Instruction Backtranslation. The basic idea is to automatically label web-text with corresponding instructions through a large language model.
The self-training approach assumes access to a base language model, a collection of unlabelled examples, e.g., a web corpus, and a small amount of seed data. The first key assumption to this method is that some portion of this massive amount of human-written text would be useful as gold generations for some user instructions. The second assumption is that we can predict instructions for these responses, which can be used to train an instruction-following model using high-quality example pairs.
The entire instruction back translation can be broken into steps:
- Self-Augment: Generate ‘good instructions’ for unlabelled data, i.e., the web corpus, to produce training data of (instruction, output) pairs for instruction tuning using Large Language Model Meta AI (LLaMA)
- Self-create: rate the generated data using LLaMA
This was then proceeded by fine-tuning LLaMA with the data and iterating the procedure using the improved model. The resulting trained Llama-based instruction backtranslation model was called ‘Humpback’ (owing to the large scale nature of whales over camels). ‘Humpback’ outperformed all the existing non-distilled models on the Alpaca Leaderboard with respect to Claude, Guanaco, Falcon-Instruct, LIMA etc.
The current procedure’s drawbacks state that enhanced data was derived from a web corpus, so the fine-tuned model may accentuate biases from web data. In conclusion, this method guarantees we will never run out of training data at all, further setting a solid scalable approach to finetune large language models to follow instructions. Future work involves scaling this method further by considering larger unlabeled corpora, which may yield further gains.
Check out the Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.