Google DeepMind Researchers Propose 6 Composable Transformations to Incrementally Increase the Size of Transformer-based Neural Networks while Preserving Functionality
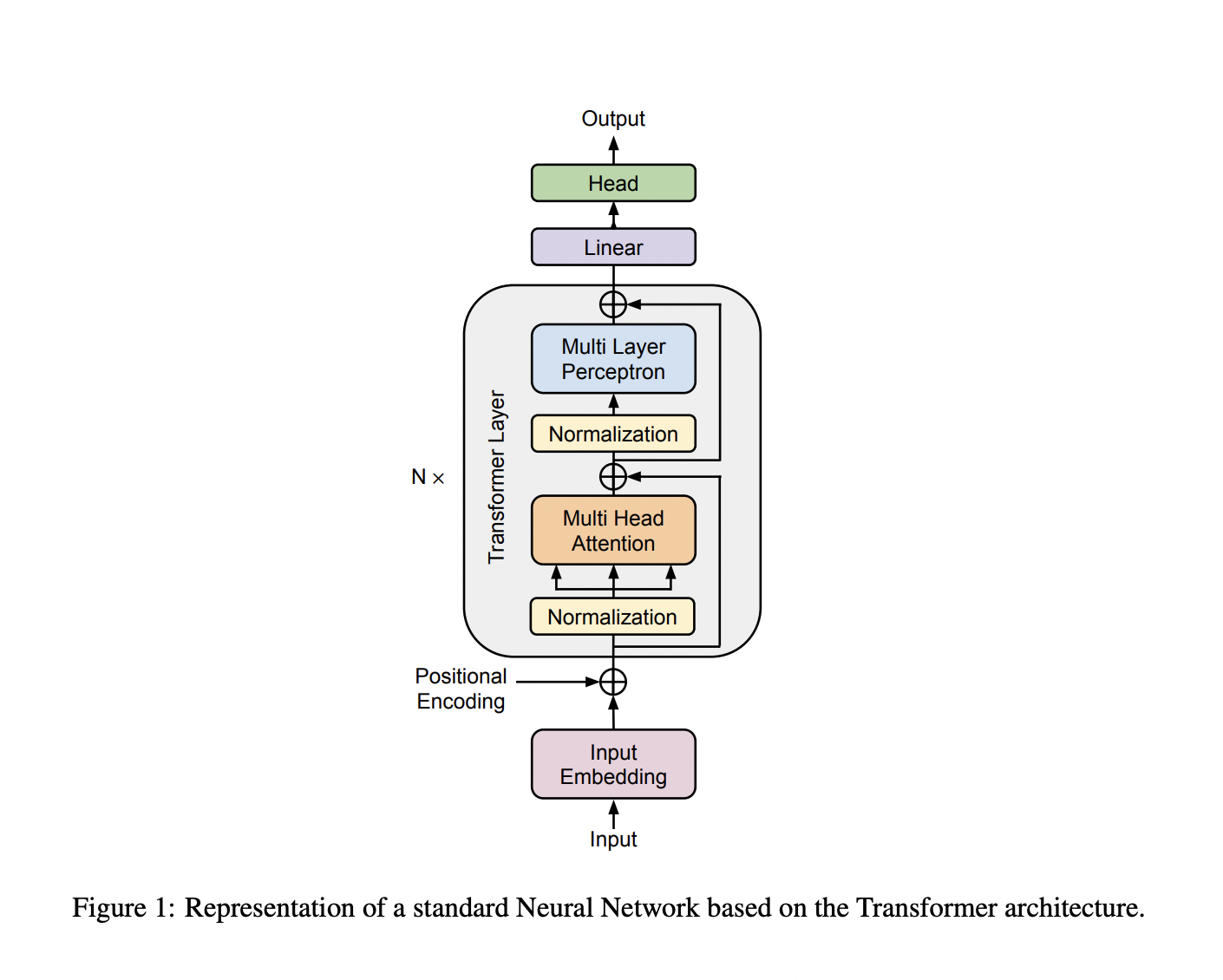
Transformer-based neural networks have received much attention lately because they function well. Machine translation, text creation, and question answering are just a few natural language processing activities for which Transformer architecture (see figure 1) has emerged as the industry standard. The effectiveness of transformer-based models is not restricted to NLP; they have also been used successfully in several other fields, such as speech recognition, computer vision, and recommendation systems. Large language, vision, and multimodal foundation models are the most complex and effective of these models, with billions to trillions of parameters.
Each new model, however, is typically taught from the start without leveraging the skills learned by earlier trained smaller models. Additionally, the model’s size remains consistent throughout training. Due to the increased quantity of training data required, the computational cost of training rises quadratically with model size. Reusing parameters from a pretrained model or dynamically increasing a model’s size during training might lower the total cost of training. However, it isn’t easy to do so without sacrificing training progress. They provide function-preserving parameter expansion transformations for transformer-based models to solve these restrictions.
These transformations increase the model size and, thus, the potential capacity of the model without changing its functionality, permitting continued training. These composable transformations operate on independent dimensions of the architecture, allowing for fine-grained architectural expansion. Some previous works have also proposed function-preserving parameter expansion transformations for transformer-based models, extending from techniques for smaller convolutional and dense models.
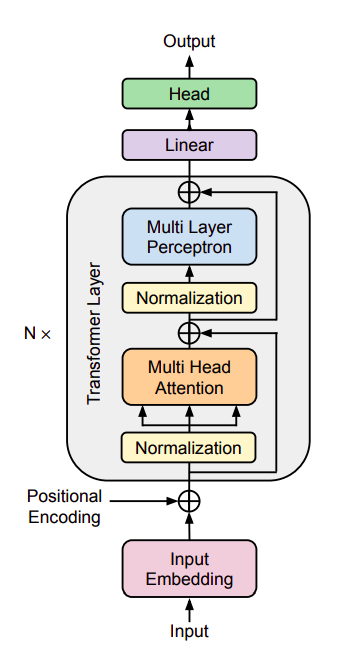
In this study researchers from Google DeepMind and University of Toulouse develop a framework that is the most extensive and modular collection of function-preserving transformations. The paper’s six contributions are the six composable function-preserving transformations that apply to Transformer architectures. They are as follows:
- The size of the MLP internal representation
- The number of attention heads
- The size of the output representation for the attention heads
- The size of the attention input representation
- The size of the input/output representations for the transformer layers
- Number of layers
They demonstrate how the precise function-preserving property is attained for each transformation with the fewest possible restrictions on the initialization of the additional parameters. The authors have discussed all these contributions in detail in the paper.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.