Unveiling Bayesian Flow Networks: A New Frontier in Generative Modeling
Generative Modeling falls under unsupervised machine learning, where the model learns to discover the patterns in input data. Using this knowledge, the model can generate new data on its own, which is relatable to the original training dataset. There have been numerous advancements in the field of generative AI and the networks used, namely autoregressive models, deep VAEs, and diffusion models. However, these models tend to have drawbacks in instances of continuous or discrete data.
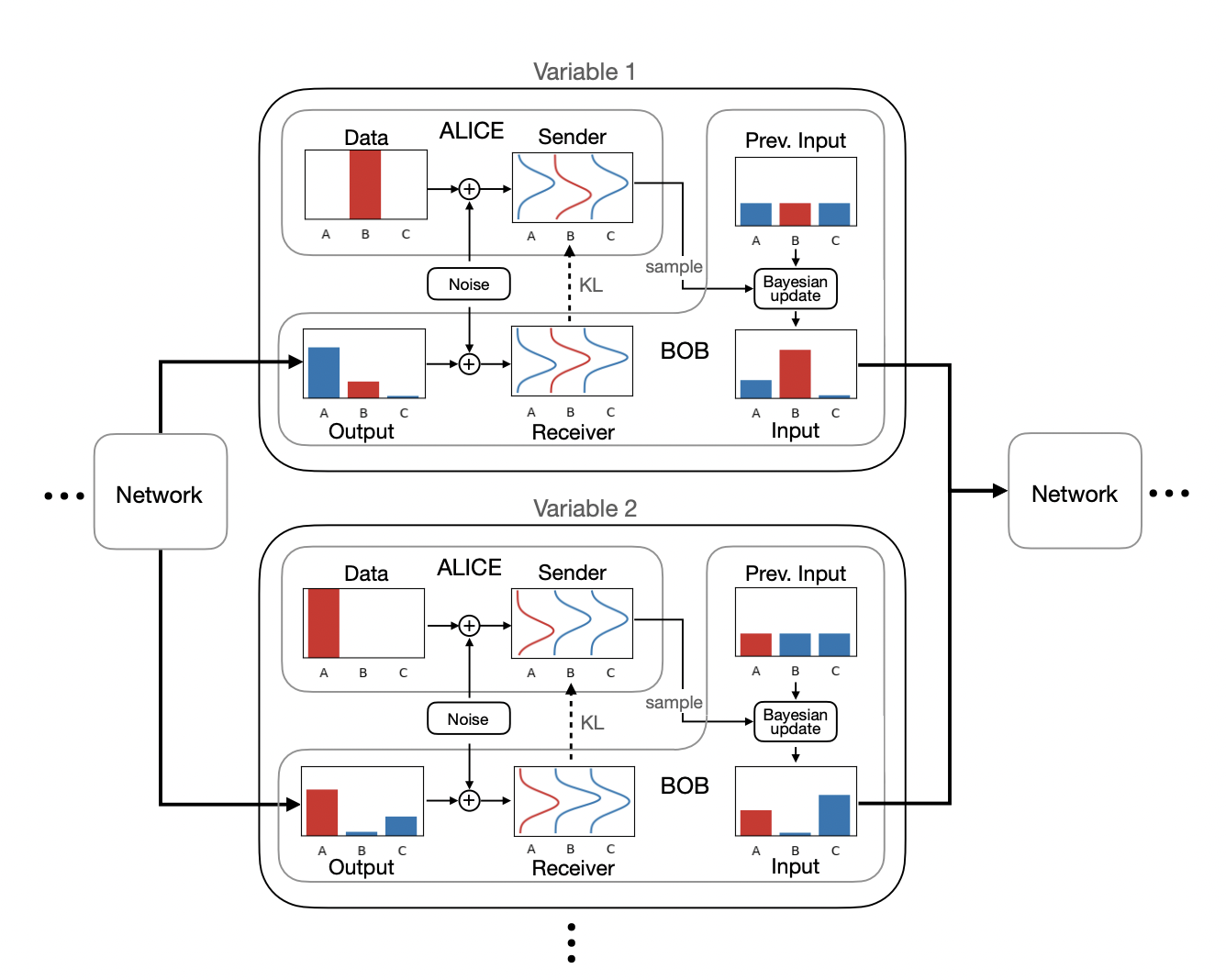
Researchers have introduced a new type of generative model called Bayesian Flow Networks (BFNs). We can think of BFNs with the help of Alice and Bob. Bob starts with a basic initial distribution. He uses its parameters in a neural network to get parameters for a new “output distribution.” Alice adds noise to the data in a planned way to make a “sender distribution.” Bob combines the output distribution with the same noise to create a “receiver distribution.” He combines hypothetical sender distributions for all possible data values, considering their probabilities according to the output distribution.
Alice sends a sample from her sender distribution to Bob. Bob updates his initial distribution using Bayesian rules based on this sample. The updates work easily if the initial distribution models each data variable separately. Bob repeats the process in multiple steps. Eventually, his predictions become accurate enough for Alice to send the data without noise.
The process described, in turn, creates a loss function for n steps, which can also be extended to continuous time by considering an infinite number of steps. In continuous time, the Bayesian updates become a Bayesian flow of information from the data to the network. A BFN trained with continuous-time loss can be run for any number of discrete steps during inference and sampling, with performance improving as the number of steps increases.
For continuous data, BFNs are most closely related to variational diffusion models, with a
very similar continuous-time loss function. The main difference, in this case, is that the network inputs are considerably less noisy in BFNs than in variational diffusion and other continuous diffusion models. This is because, generally, the generative process of BFNs begins with the parameters of a fixed prior, whereas that of diffusion models begins with pure noise.
Researchers have drawn the framework of BFNs to be applied to continuous, discrete, discretized data. Experimental results were carried out over CIFAR-10 (32×32 8-bit color images), dynamically binarized MNIST (28×28 binarized images of handwritten digits), and text8 (length 256 character sequences with a size 27 alphabet), and BFN outperformed on all benchmarks. This study has put a fresh perspective on BFNs in generative modeling and opened up more avenues in this domain.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.