Evaluating Large Language Models: Meet AgentSims, A Task-Based AI Framework for Comprehensive and Objective Testing
LLMs have changed the way language processing (NLP) is thought of, but the issue of their evaluation persists. Old standards eventually become irrelevant, given that LLMs can perform NLU and NLG at human levels (OpenAI, 2023) using linguistic data.
In response to the urgent need for new benchmarks in areas like close-book question-answer (QA)-based knowledge testing, human-centric standardized exams, multi-turn dialogue, reasoning, and safety assessment, the NLP community has come up with new evaluation tasks and datasets that cover a wide range of skills.
The following issues persist, however, with these updated standards:
- The task formats impose constraints on the evaluable abilities. Most of these activities use a one-turn QA style, making them inadequate for gauging LLMs’ versatility as a whole.
- It is simple to manipulate benchmarks. When determining a model’s efficacy, it is crucial that the test set not be compromised in any way. However, with so much LLM information already trained, it’s increasingly likely that test cases will be mixed in with the training data.
- The currently available metrics for open-ended QA are subjective. Traditional open-ended QA measures have included both objective and subjective human grading. In the LLM era, measurements based on matching text segments are no longer relevant.
Researchers are currently using automatic raters based on well-aligned LLMs like GPT4 to lower the high cost of human rating. While LLMs are biased toward certain traits, the biggest issue with this method is that it cannot analyze supra-GPT4-level models.
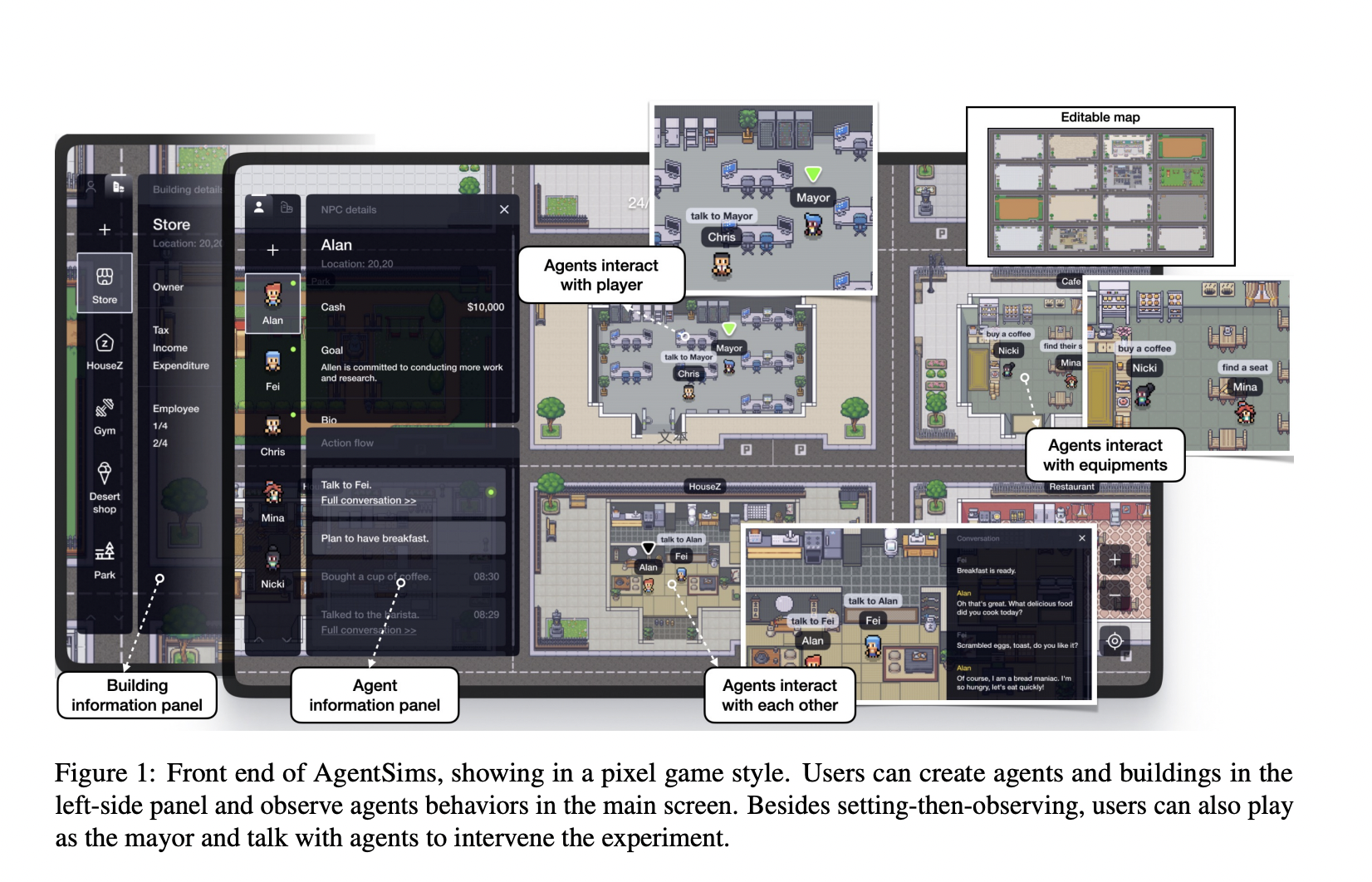
Recent studies by PTA Studio, Pennsylvania State University, Beihang University, Sun Yat-sen University, Zhejiang University, and East China Normal University present AgentSims, an architecture for curating evaluation tasks for LLMs that is interactive, visually appealing, and programmatically based. The primary goal of AgentSims is to facilitate the task design process by removing barriers that researchers with varying levels of programming expertise may face.
Researchers in the field of LLM can take advantage of AgentSims’ extensibility and combinability to examine the effects of combining multiple plans, memory, and learning systems. AgentSims’s user-friendly interface for map generation and agent management makes it accessible to specialists in subjects as diverse as behavioral economics and social psychology. A user-friendly design like this one is crucial to the continued growth and development of the LLM sector.
The research paper says that AgentSims is better than current LLM benchmarks, which only test a small number of skills and use test data and criteria that are open to interpretation. Social scientists and other non-technical users can quickly create environments and design jobs using the graphical interface’s menus and drag-and-drop features. By modifying the code’s abstracted agent, planning, memory, and tool-use classes, AI professionals and developers can experiment with various LLM support systems. The objective task success rate can be determined by goal-driven evaluation. In sum, AgentSims facilitates cross-disciplinary community development of robust LLM benchmarks based on varied social simulations with explicit goals.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.