This AI Research Addresses the Problem of ‘Loss of Plasticity’ in Deep Learning Systems When Used in Continual Learning Settings
Modern deep-learning algorithms are now focused on problem environments where training occurs just once on a sizable data collection, never again—all of the early triumphs of deep learning in voice recognition and picture classification employed such train-once settings. Replay buffers and batching were later added to deep understanding when applied to reinforcement learning, making it extremely close to a train-once setting. A large batch of data was also used to train recent deep learning systems like GPT-3 and DallE. The most popular approach in these situations has been to gather data continuously and then occasionally prepare a new network from scratch in a training configuration. Of course, in many applications, the data distribution varies over time, and training must continue in some manner. Modern deep-learning techniques were developed with the train-once setting in mind.
In contrast, the perpetual learning problem setting focuses on continuously learning from fresh data. The ongoing learning option is ideal for issues where the learning system must deal with a dynamic data stream. For instance, think of a robot that has to find its way around a house. The robot would have to be retrained from scratch or run the danger of being rendered useless every time the house’s layout changed if the train-once setting was used. It would be necessary to retrain from scratch if the design changed regularly. On the other hand, the robot might easily learn from the new information and continuously adjust to the changes in the house under the ongoing learning scenario. The importance of lifelong learning has grown in recent years, and more specialized conferences are being held to address it, such as the Conference on Life-long Learning Agents (CoLLAS).
They emphasize the environment of ongoing learning in their essay. When exposed to fresh data, deep learning systems frequently lose most of what they have previously learned, a condition known as “catastrophic forgetting.” In other words, deep learning techniques do not retain stability in ongoing learning issues. In the late 1900s, early neural networks were the first to demonstrate this behavior. Catastrophic forgetting has recently gotten fresh interest due to the development of deep learning since several articles have been written about preserving stability in deep continuous learning.
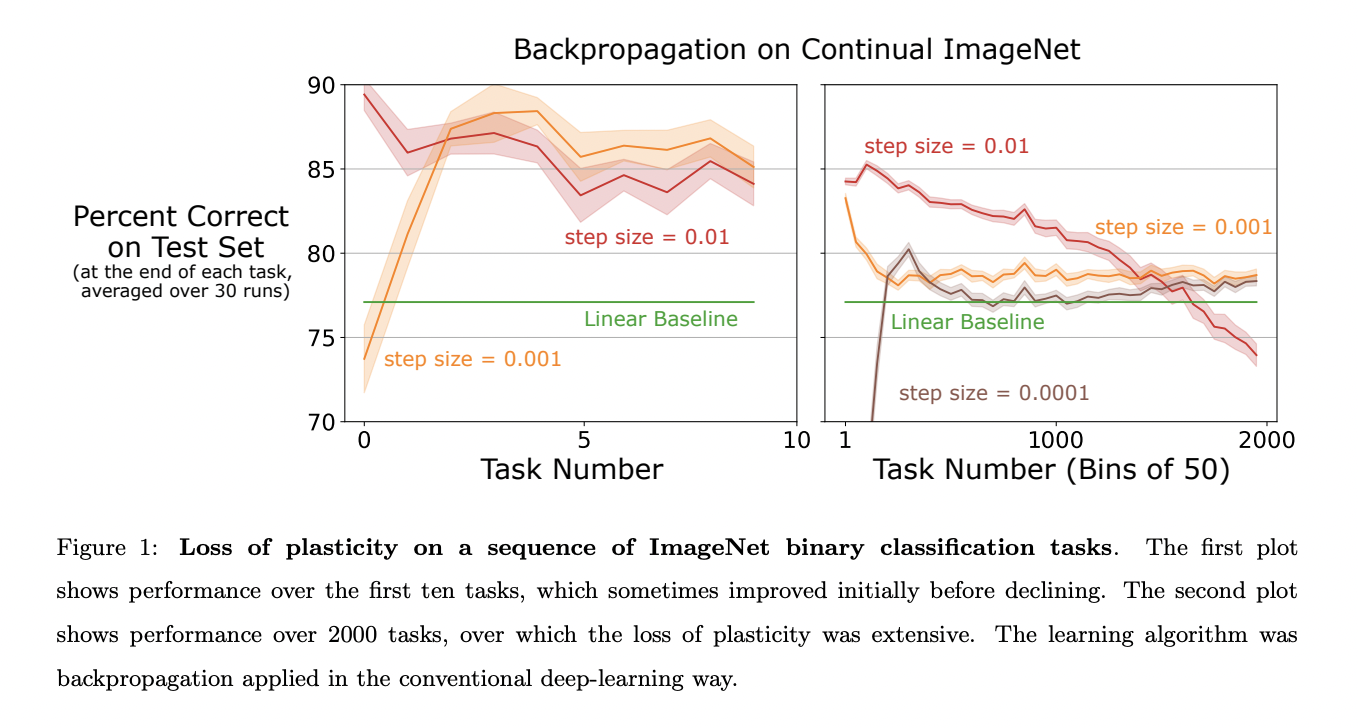
The capacity to continue learning from fresh material is distinct from catastrophic forgetting and perhaps more essential to continuous learning. They call this capacity “plasticity.”Continuous learning systems must maintain plasticity because it enables them to adjust to changes in their data streams. If their data stream changes, continuously learning systems that lose flexibility may become worthless. They emphasize the problem of flexibility loss in their essay. These studies employed a configuration in which the network was first shown a collection of instances for a predetermined number of epochs, after which the training set was enlarged with new examples, and the training cycle repeated for an extra number of epochs. After accounting for the number of epochs, they discovered that the error for the cases in the first training set was lower than for the later-added examples. These publications offered proof that the loss of flexibility caused by deep learning and the backpropagation algorithm upon which it is based is a common occurrence.
New outputs, known as heads, were added to the network in its configuration when a new job was offered, and the number of outputs increased as more tasks were encountered. Thus, the effects of interference from old heads were mixed up with the consequences of plasticity loss. According to Chaudhry et al., the loss of plasticity was modest when old heads were taken out at the beginning of a new task, indicating that the major cause of the loss of plasticity they saw was interference from old heads. The fact that previously researchers only employed ten challenges prevented them from measuring the loss of plasticity that occurs when deep learning techniques are presented with a lengthy list of tasks.
Although the findings in these publications suggest that deep learning systems have lost some of their essential adaptability, no one has yet shown that continuous learning has lost plasticity. In the reinforcement learning field, where recent works have demonstrated a significant loss of plasticity, there is more evidence for the loss of plasticity in contemporary deep learning. By demonstrating that early learning in reinforcement learning issues can have a negative impact on later learning, Nishikin et al. coined the term “primacy bias.”
Given that reinforcement learning is fundamentally continuous as a consequence of changes in the policy, this result may be attributable to deep learning networks losing their flexibility in circumstances where learning is ongoing. Additionally, Lyle et al. demonstrated that some deep reinforcement learning agents may eventually lose their capacity to pick up new skills. These are significant data points, but because of the intricacy of contemporary deep reinforcement learning, it isn’t easy to make any firm conclusions. These studies show that deep learning systems lose flexibility but fall short of providing a complete explanation of the phenomenon. These studies include those from the psychology literature around the turn of the century and more contemporary ones in machine learning and reinforcement learning. In this study, researchers from the Department of Computing Science, University of Alberta, and CIFAR AI Chair, Alberta Machine Intelligence Institute provide a more conclusive response to plasticity loss in contemporary deep learning.
They demonstrate that persistent supervised learning issues cause deep learning approaches to lose plasticity and that this plasticity loss can be severe. In a continuous supervised learning problem using the ImageNet dataset and including hundreds of learning trials, they first show that deep learning suffers from loss of plasticity. The complexity and related confusion that always develop in reinforcement learning are eliminated when supervised learning tasks are used instead. We can also determine the complete amount of the loss of plasticity thanks to the hundreds of tasks that we have. They next prove the universality of deep learning’s lack of flexibility over a wide variety of hyperparameters, optimizers, network sizes, and activation functions using two computationally less expensive problems (a variation of MNIST and the slowly changing regression problem). They want a deeper grasp of its origins after demonstrating the severity and generality of loss of flexibility in deep learning.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.