Meet AnomalyGPT: A Novel IAD Approach Based on Large Vision-Language Models (LVLM) to Detect Industrial Anomalies
On various Natural Language Processing (NLP) tasks, Large Language Models (LLMs) such as GPT-3.5 and LLaMA have displayed outstanding performance. The capacity of LLMs to interpret visual information has more recently been expanded by cutting-edge techniques like MiniGPT-4, BLIP-2, and PandaGPT by aligning visual aspects with text features, ushering in a huge shift in the field of artificial general intelligence (AGI). The potential of LVLMs in IAD tasks is constrained even though they have been pre-trained on large amounts of data obtained from the Internet. Additionally, their domain-specific knowledge is only moderately developed, and they need more sensitivity to local features inside objects. The IAD assignment tries to find and pinpoint abnormalities in photographs of industrial products.
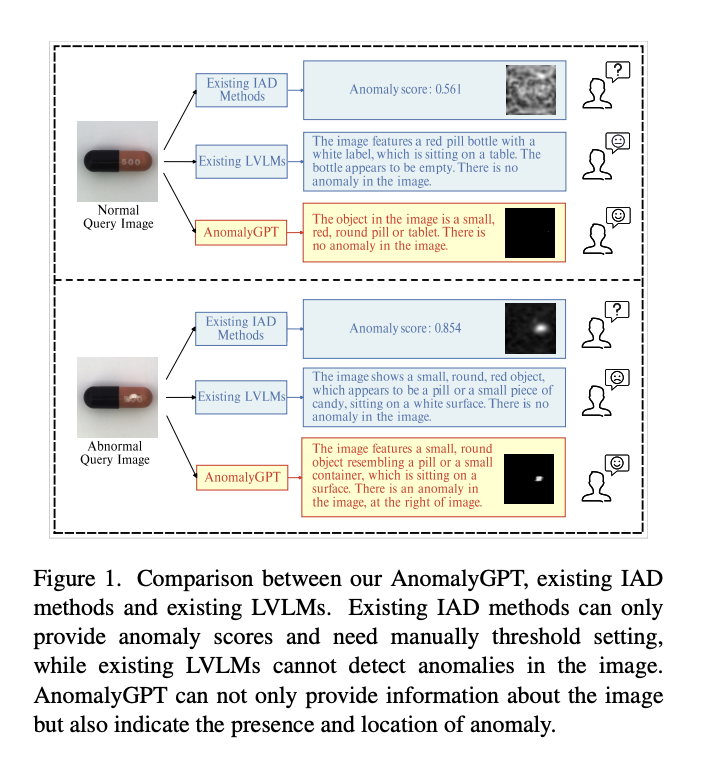
Models must be trained only on normal samples to identify anomalous samples that depart from normal samples since real-world examples are uncommon and unpredictable. Most current IAD systems only offer anomaly scores for test samples and ask for manually defining criteria to tell apart normal from anomalous instances for each class of objects, making them unsuitable for actual production settings. Researchers from Chinese Academy of Sciences, University of Chinese Academy of Sciences, Objecteye Inc., and Wuhan AI Research present AnomalyGPT, a unique IAD methodology based on LVLM, as shown in Figure 1, as neither existing IAD approaches nor LVLMs can adequately handle the IAD problem. Without requiring manual threshold adjustments, AnomalyGPT can identify anomalies and their locations.

Additionally, their approach may offer picture information and promote interactive interaction, allowing users to pose follow-up queries depending on their requirements and responses. With just a few normal samples, AnomalyGPT can also learn in context, allowing for quick adjustment to new objects. They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise. Direct training using IAD data, however, needs to be improved. Data scarcity is the first. Pre-trained on 160k photos with associated multi-turn conversations, including techniques like LLaVA and PandaGPT. However, the small sample sizes of the IAD datasets currently available make direct fine-tuning vulnerable to overfitting and catastrophic forgetting.
To fix this, they fine-tune the LVLM using prompt embeddings rather than parameter fine-tuning. After picture inputs, more prompt embeddings are inserted, adding additional IAD information to the LVLM. The second difficulty has to do with fine-grained semantics. They suggest a simple, visual-textual feature-matching-based decoder to get pixel-level anomaly localization findings. The decoder’s outputs are made available to the LVLM and the original test pictures through prompt embeddings. This enables the LVLM to use both the raw image and the decoder’s outputs to identify anomalies, increasing the precision of its judgments. On the MVTec-AD and VisA databases, they undertake comprehensive experiments.
They attain an accuracy of 93.3%, an image-level AUC of 97.4%, and a pixel-level AUC of 93.1% with unsupervised training on the MVTec-AD dataset. They attain an accuracy of 77.4%, an image-level AUC of 87.4%, and a pixel-level AUC of 96.2% when one shot is transferred to the VisA dataset. On the other hand, one-shot transfer to the MVTec-AD dataset following unsupervised training on the VisA dataset produced an accuracy of 86.1%, an image-level AUC of 94.1%, and a pixel-level AUC of 95.3%.
The following is a summary of their contributions:
• They present the innovative use of LVLM for handling IAD duty. Their approach facilitates multi-round discussions and detects and localizes anomalies without manually adjusting thresholds. Their work’s lightweight, visual-textual feature-matching-based decoder addresses the limitation of the LLM’s weaker discernment of fine-grained semantics. It alleviates the constraint of LLM’s restricted ability to generate text outputs. To their knowledge, they are the first to apply LVLM to industrial anomaly detection successfully.
• To preserve the LVLM’s intrinsic capabilities and enable multi-turn conversations, they train their model concurrently with the data used during LVLM pre-training and use prompt embeddings for fine-tuning.
• Their approach maintains strong transferability and can do in-context few-shot learning on new datasets, producing excellent results.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.