This AI Research Unveils ComCLIP: A Training-Free Method in Compositional Image and Text Alignment
Compositional image and text matching present a formidable challenge in the dynamic field of vision-language research. This task involves precisely aligning subject, predicate/verb, and object concepts within images and textual descriptions. This challenge has profound implications for various applications, including image retrieval, content understanding, and more. Despite the significant advancements made by pretrained vision-language models like CLIP, there remains a crucial need for improvement in achieving compositional performance, which often eludes existing systems. The heart of the challenge lies in the biases and spurious correlations that can become ingrained within these models during their extensive training process. In this context, the researchers delve into the core problem and introduce a groundbreaking solution called ComCLIP.
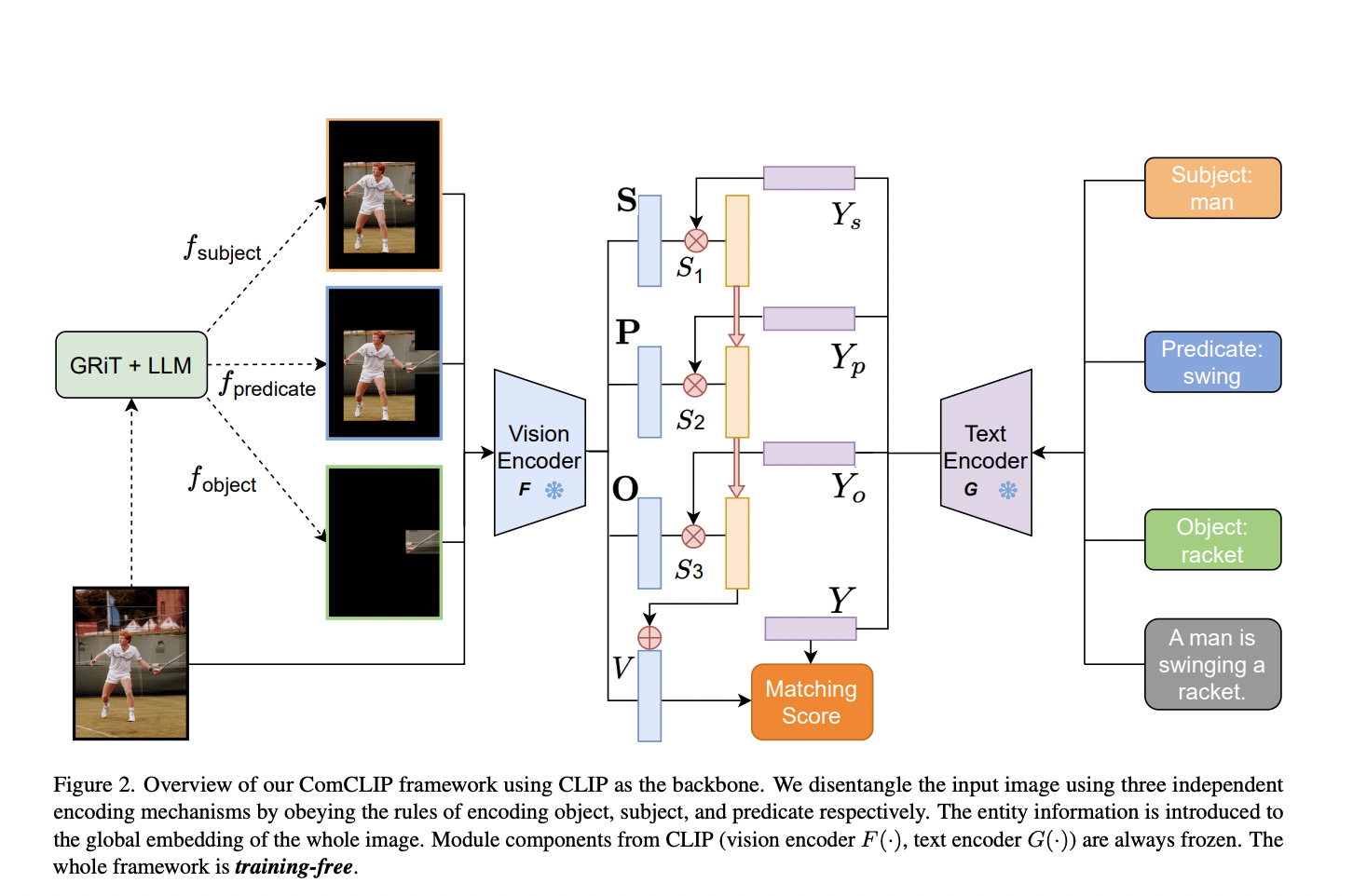
In the current landscape of image-text matching, where CLIP has made significant strides, the conventional approach treats images and text as holistic entities. While this approach works effectively in many cases, it often needs to improve in tasks that require fine-grained compositional understanding. This is where ComCLIP takes a bold departure from the status quo. Rather than treating images and text as monolithic wholes, ComCLIP dissects input images into their constituent parts: subjects, objects, and action sub-images. It does so by adhering to specific encoding rules that govern the segmentation process. By dissecting images in this manner, ComCLIP gains a deeper understanding of the distinct roles played by these different components. Moreover, ComCLIP employs a dynamic evaluation strategy that assesses the importance of these various components in achieving precise compositional matching. This innovative approach has the potential to mitigate the impact of biases and spurious correlations inherited from pretrained models, promising superior compositional generalization without the need for additional training or fine-tuning.

ComCLIP’s methodology involves several key components that harmonize to address the compositional image and text matching challenge. It begins with processing the original image using a dense caption module, which generates dense image captions focusing on objects within the scene. Simultaneously, the input text sentence undergoes a parsing process. During parsing, entity words are extracted and meticulously organized into a subject-predicate-object format, mirroring the structure found in the visual content. The magic happens when ComCLIP establishes a robust alignment between these dense image captions and the extracted entity words. This alignment is a bridge, effectively mapping entity words to their corresponding regions within the image based on the dense captions.
One of the key innovations within ComCLIP is the creation of predicate sub-images. These sub-images are meticulously crafted by combining relevant object and subject sub-images, mirroring the action or relationship described in the textual input. The resulting predicate sub-images visually represent the actions or relationships, further enriching the model’s understanding. With the original sentence and image, along with their respective parsed words and sub-images, ComCLIP then proceeds to employ the CLIP text and vision encoders. These encoders transform the textual and visual inputs into embeddings, effectively capturing the essence of each component. ComCLIP computes cosine similarity scores between each image embedding and the corresponding word embeddings to assess the relevance and importance of these embeddings. These scores are then subjected to a softmax layer, enabling the model to accurately weigh the significance of different components. Finally, ComCLIP combines these weighted embeddings to obtain the final image embedding—a representation that encapsulates the essence of the entire input.

In conclusion, this research illuminates the critical challenge of compositional image and text matching within vision-language research and introduces ComCLIP as a pioneering solution. ComCLIP’s innovative approach, firmly rooted in the principles of causal inference and structural causal models, revolutionizes how we approach compositional understanding. ComCLIP promises to significantly enhance our ability to understand and work with compositional elements in images and text by disentangling visual input into fine-grained sub-images and employing dynamic entity-level matching. While existing methods like CLIP and SLIP have demonstrated their value, ComCLIP stands out as a promising step forward, addressing a fundamental problem in the field and opening new avenues for research and application.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.