Bridging the Gap Between Clinicians and Language Models in Healthcare: Meet MedAlign, a Clinician-Generated Dataset for Instruction Following Electronic Medical Records
Large Language Models (LLMs) have utilized the capabilities of Natural Language Processing in a great way. From language production and reasoning to reading comprehension, LLMs can do it all. The potential for these models to help physicians in their work has attracted attention in a number of disciplines, including healthcare. Recent LLMs, including Med-PaLM and GPT-4, have proven their proficiency in tasks involving medical question-answering, particularly those involving medical databases and exams.
A constant limitation has been the difficulty in determining whether LLMs’ outstanding performance in controlled benchmarks translates to actual clinical contexts. Clinicians carry out a variety of information-related duties in the healthcare industry, and these jobs frequently require complicated, unstructured data from Electronic Health Records (EHRs). The complexity and intricacies that healthcare practitioners deal with are not well represented in the question-answering datasets for EHR data that are currently available. When physicians rely on LLMs to help them, they lack the nuance needed to assess how well such models can deliver precise and context-aware replies.
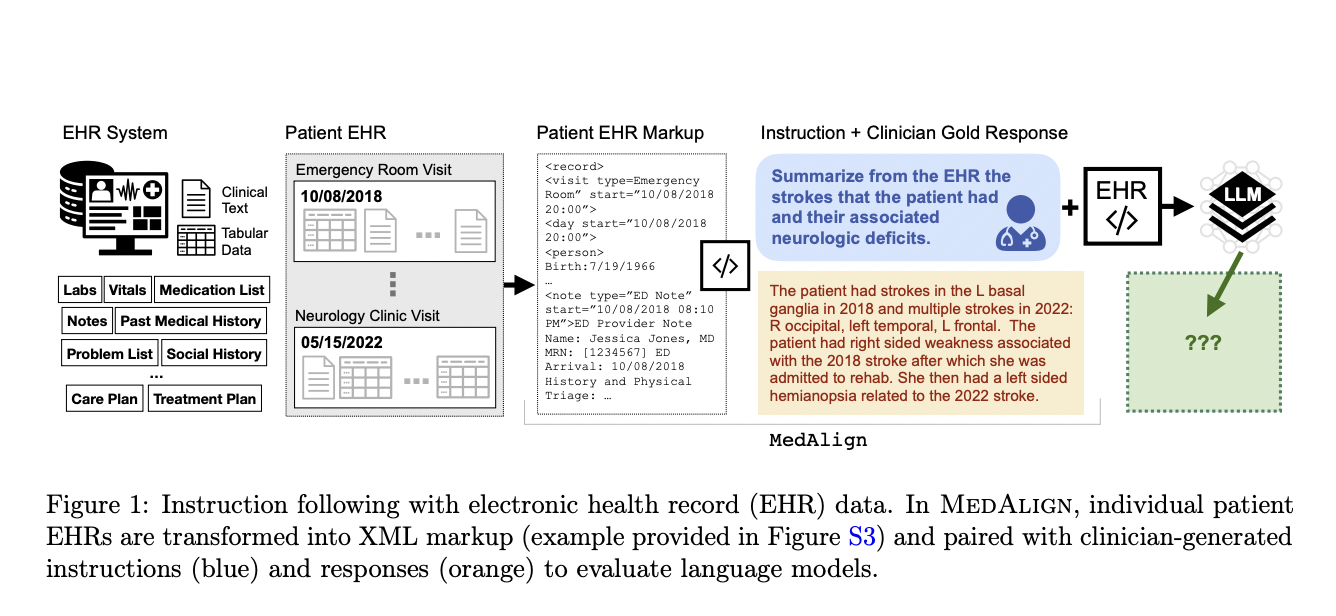
To overcome these limitations, a team of researchers has developed MedAlign, a benchmark dataset that comprises a total of 983 questions and instructions submitted by 15 practicing clinicians who specialize in 7 different medical specialties. MedAlign focuses on EHR-based instruction-answer pairings rather than merely question-answer pairs, which makes it different from other datasets. The team has included clinician-written reference responses for 303 of these instructions and linked them with EHR data to offer context and foundation for the prompts. Each clinician assessed and ranked the responses produced by six various LLMs on these 303 instructions in order to confirm the dataset’s dependability and quality.
Clinicians have also provided their own gold-standard solutions. In assembling a dataset that includes clinician-provided instructions, expert assessments of LLM-generated responses, and the related EHR context, MedAlign has marked a trailblazing endeavor. This dataset differs from others because it provides a useful tool for evaluating how well LLMs work in clinical situations.
The second contribution demonstrates the viability of an automated, retrieval-based method for matching pertinent patient electronic health records with clinical instructions. To do this, the team has created a procedure that would make asking clinicians for instructions more effective and scalable. They could seek submissions from a larger and more varied set of clinicians by isolating this instruction-soliciting method.
They have even evaluated how well their automated method matched instructions with pertinent EHRs. The findings revealed that, compared to random pairings of instructions with EHRs, this automated matching procedure successfully provided relevant pairings in 74% of situations. This result highlights the opportunity for automation to increase the effectiveness and precision of connecting clinical data.
The final contribution examines the relationship between automated Natural Language Generation (NLG) parameters and physician ratings of LLM-generated responses. This investigation seeks to determine whether scalable, automated measures can be used to rank LLM replies in place of professional clinician evaluations. The team aims to lessen the need for doctors to manually identify and rate LLM replies in future studies by measuring the degree of agreement between human expert ranks and automated criteria. The creation and improvement of LLMs for healthcare applications may be sped up as a result of this endeavor to make the review process more effective and less dependent on human resources.
Check out the Paper, GitHub, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.