A Powerful Fully Permissively-Licensed Language Model with
In recent times, the field of artificial intelligence has witnessed remarkable progress, particularly in the development of language models. At Marktechpost Media, we have covered many language models based on various parameters and SOTA performance. Following this trend, we have another release, and this time, it is from Adept AI Labs releasing Persimmon-8B. Persimmon-8B is an open-source, fully permissively licensed model in the 8B class. This model holds immense potential for a wide array of applications, aiming to assist users in various computer-related tasks. However, it is important to note that in its raw form, the model may produce outputs that are not curated for potential toxicity. This raises a critical concern about the need for more refined evaluation techniques.
While smaller language models have demonstrated impressive capabilities, Persimmon-8B stands out as a significant leap forward. It boasts a context size four times that of LLaMA2 and eight times that of models like GPT-3, enabling it to tackle context-bound tasks with greater finesse. Moreover, its performance is on par with, if not surpassing, other models in its size range despite being trained on significantly less data. This exemplifies the efficiency and effectiveness of the model’s training process.
To evaluate the prowess of Persimmon-8B, the Adept team employs a unique approach. Instead of relying solely on implicit probabilities, they opt for a more direct interaction, where the model is tasked with generating answers. This methodology mirrors real-world interactions with language models, where users pose questions and anticipate responses. By releasing their prompts, Adept invites the community to reproduce and validate their findings.
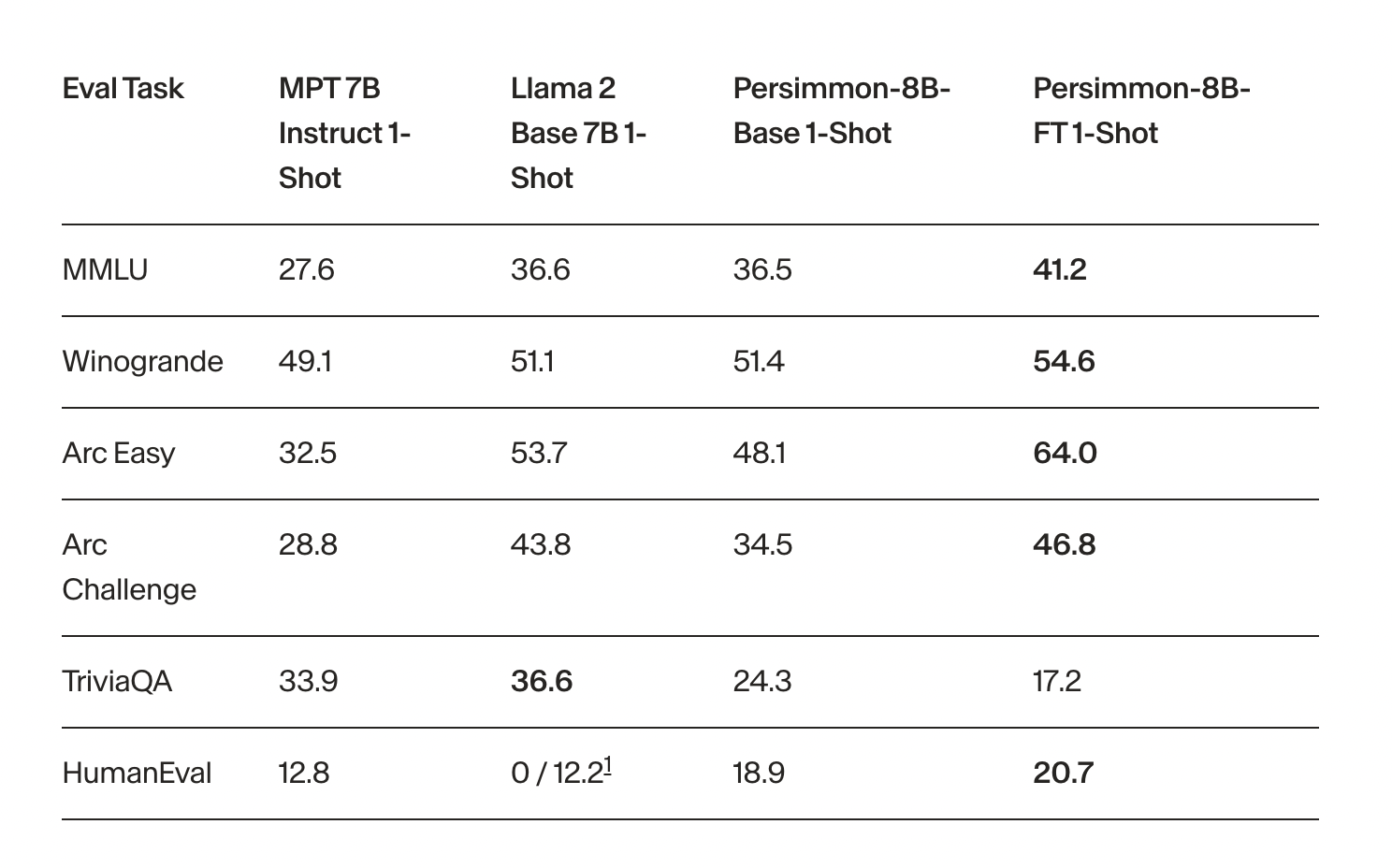
The results speak volumes about the capabilities of Persimmon-8B. Compared to other models in its size range, such as LLama 2 and MPT 7B Instruct, Persimmon-8B-FT emerges as the strongest performer across various metrics. Even the base model, Persimmon-8B-Base, demonstrates comparable performance to LLama 2 despite having been trained on a fraction of the data. This underscores the model’s efficiency and effectiveness in handling a diverse range of tasks.
Delving into the technical details, Persimmon-8B is a decoder-only transformer with several architectural enhancements. It leverages squared ReLU activation and rotary positional encodings, outperforming conventional alternatives. The model’s checkpoint contains approximately 9.3 billion parameters optimized for efficient training. Notably, the decoupling of input and output embeddings serves as a system-level enhancement, streamlining the training process.
In terms of inference speed, Persimmon-8B exhibits impressive performance. With the use of optimized code, it can generate approximately 56 tokens per second on a single 80GB A100 GPU. This positions it as a highly efficient tool for real-time applications.
In conclusion, the release of Persimmon-8B marks a significant milestone in the field of language models. Its capabilities, coupled with the innovative evaluation approach employed by Adept, pave the way for a new era of interactive AI applications. By open-sourcing this model, Adept invites the community to build upon its foundation and drive further innovation in this dynamic field. As the model’s adoption grows, it is likely to find applications in an array of domains, revolutionizing how people interact with computer systems.
Check out the Adept Blog and GitHub link. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.