A New AI Research from Apple and Equall AI Uncovers Redundancies in Transformer Architecture: How Streamlining the Feed Forward Network Boosts Efficiency and Accuracy
Transformer design that has recently become popular has taken over as the standard method for Natural Language Processing (NLP) activities, particularly Machine Translation (MT). This architecture has displayed impressive scaling qualities, which means that adding more model parameters results in better performance on a variety of NLP tasks. A number of studies and investigations have validated this observation. Though transformers excel in terms of scalability, there is a parallel movement to make these models more effective and deployable in the real world. This entails taking care of issues with latency, memory use, and disc space.
Researchers have been actively investigating methods to address these issues, including component trimming, parameter sharing, and dimensionality reduction. The widely utilized Transformer architecture comprises a number of essential parts, of which two of the most important ones are the Feed Forward Network (FFN) and Attention.
- Attention – The Attention mechanism allows the model to capture relationships and dependencies between words in a sentence, irrespective of their positions. It functions as a sort of mechanism to aid the model in determining which portions of the input text are most pertinent to each word it is currently analyzing. Understanding the context and connections between words in a phrase depends on this.
- Feed Forward Network (FFN): The FFN is responsible for non-linearly transforming each input token independently. It adds complexity and expressiveness to the model’s comprehension of each word by performing specific mathematical operations on the representation of each word.
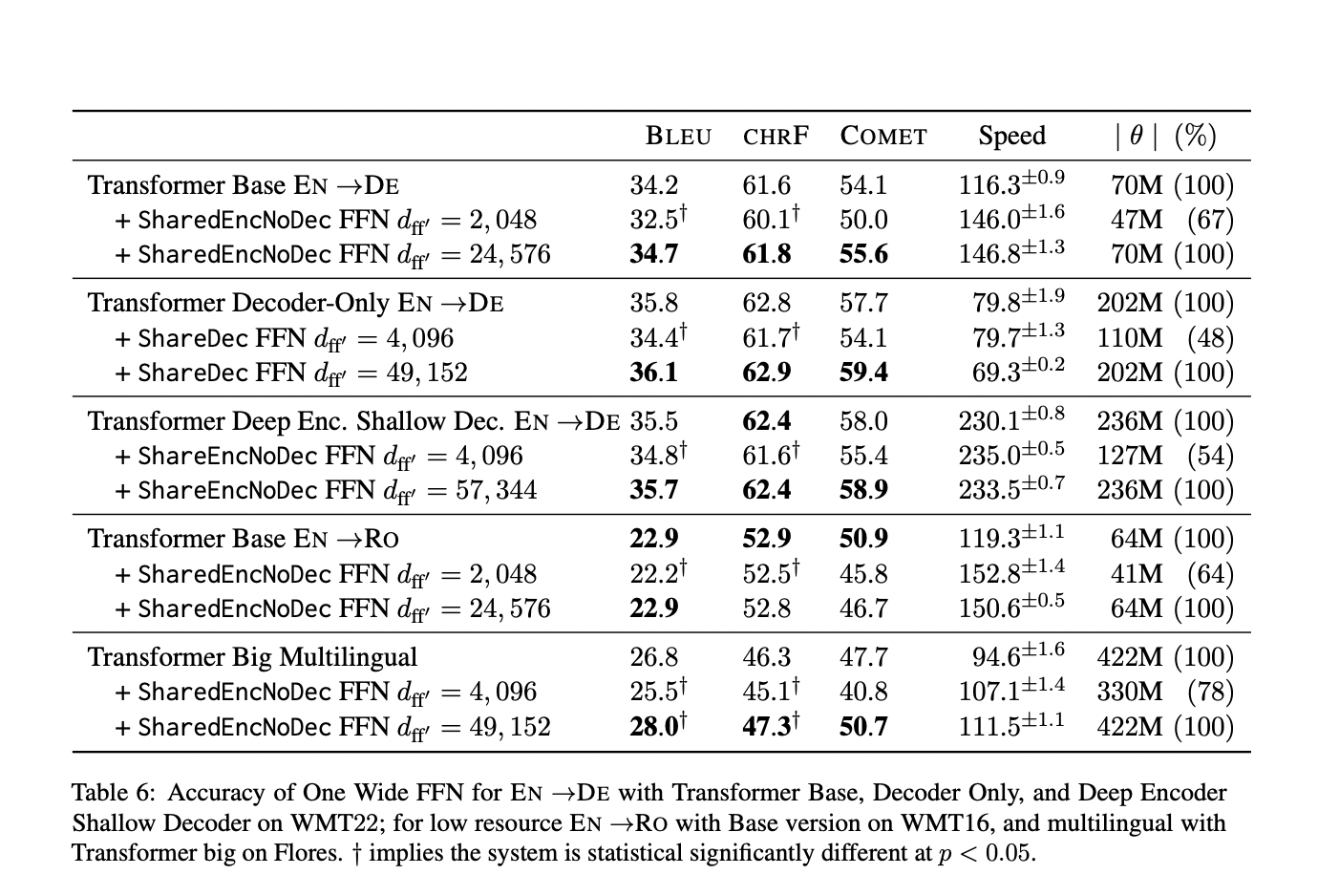
In recent research, a team of researchers has focused on investigating the role of the FFN within the Transformer architecture. They have discovered that the FFN exhibits a high level of redundancy while being a large component of the model and consuming a significant number of parameters. They have found that they could scale back the model’s parameter count without significantly compromising accuracy. They have achieved this by removing the FFN from the decoder layers and instead using a single shared FFN across the encoder layers.
- Decoder Layers: Each encoder and decoder in a standard Transformer model has its own FFN. The researchers eliminated the FFN from the decoder layers.
- Encoder Layers: They used a single FFN that was shared by all of the encoder layers rather than having individual FFNs for each encoder layer.
The researchers have shared the benefits that have accompanied this approach, which are as follows.
- Parameter Reduction: They drastically decreased the amount of parameters in the model by deleting and sharing the FFN components.
- The model’s accuracy only decreased by a modest amount despite removing a sizable number of its parameters. This shows that the encoder’s numerous FFNs and the decoder’s FFN have some degree of functional redundancy.
- Scaling Back: They expanded the hidden dimension of the shared FFN to restore the architecture to its previous size while maintaining or even enhancing the performance of the model. Compared to the previous large-scale Transformer model, this resulted in considerable improvements in accuracy and model processing speed, i.e., latency.
In conclusion, this research shows that the Feed Forward Network in the Transformer design, especially in the decoder levels, may be streamlined and shared without significantly affecting model performance. This not only lessens the model’s computational load but also improves its effectiveness and applicability for diverse NLP applications.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.