Meet ResFields: A Novel AI Approach to Overcome the Limitations of Spatiotemporal Neural Fields in Effectively Modeling Long and Complex Temporal Signals
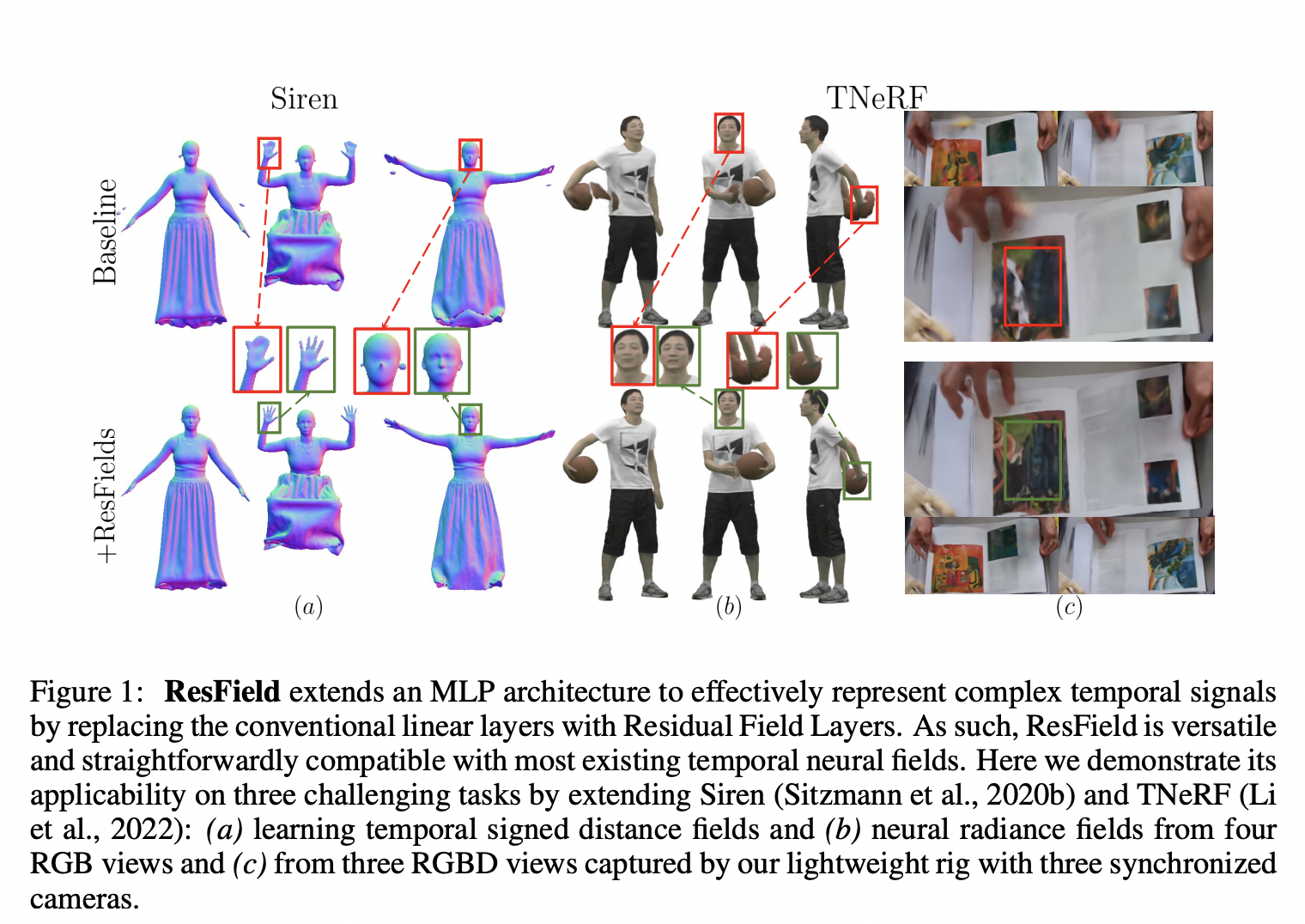
The most popular neural network architecture for representing neural continuous spatiotemporal fields, also known as neural fields, is the multi-layer perceptron. This is because it can encode continuous signals over arbitrary dimensions, has built-in implicit regularisation, and has a spectral bias that facilitates effective interpolation. Thanks to these exceptional features, MLPs have achieved great success in various applications, including image synthesis, animation, texture creation, and innovative view synthesis. However, collecting fine-grained features and effectively replicating complicated real-world signals are both difficult because of the spectral bias of MLPs, which is the tendency of neural networks to learn functions with low frequencies.
Positional encoding or unique activation functions have been used in earlier attempts to overcome the spectrum bias. However, capturing fine-grained features is difficult even with these techniques, especially when working with big spatiotemporal data like lengthy films or dynamic 3D sceneries. Increasing the network complexity in terms of the total number of neurons is an easy technique to boost the capacity of MLPs. However, because the time and memory complexity grows about the total number of parameters, such a technique would result in slower inference and optimization and more costly GPU RAM.
The problem they want to solve in this research is increasing model capacity without compromising the architecture, input encoding, or activation functions of MLP neural fields. At the same time, they want to preserve neural networks’ implicit regularisation property and add to the methods already in use for spectral bias reduction. The fundamental concept is to replace one or more MLP layers with time-dependent layers whose weights are represented as trainable residual parameters Wi(t) added to the pre-existing layer weights Wi. Researchers from ETH Zurich, Microsoft, and the University of Zurich refer to the neural fields created in this manner as ResFields.
Meta-learning MLP weights and maintaining specialized separate parameters is another option, but this requires long training that does not scale to photo-realistic reconstructions. Partitioning the spatiotemporal field and fitting different/local neural areas is the most common method for boosting modeling capability. However, these techniques impede global reasoning and generalization because of local gradient changes to grid structures, which are crucial for radiance field reconstruction from sparse views. This method of increasing model capacity has three main benefits.
First, the inference and training speed are maintained since the underlying MLP does not widen. This characteristic is essential for most real-world downstream neural field applications, such as NeRF, which aims to address inverse volume rendering by repeatedly querying neural fields. Second, unlike other approaches that emphasize spatial partitioning, this modeling maintains the implicit regularisation and generalization capabilities of MLPs. Last, ResFields are adaptable, simple to expand, and work with most MLP-based algorithms for spatiotemporal data. However, because so many trainable parameters aren’t limited, the simple implementation of ResFields can result in diminished interpolation qualities.
They suggest implementing the residual parameters as a global low-rank spanning set and a set of time-dependent coefficients, drawing inspiration from well-studied low-rank factorized layers. This modeling improves the generalization qualities and significantly minimizes the memory footprint brought on by storing extra network parameters.
Their main contributions are, in brief, as follows:
• They introduce ResFields, an architecture-independent building component for modeling spatiotemporal fields.
• They methodically show how their approach enhances several other existing approaches.
• They exhibit cutting-edge outcomes for four difficult tasks: neural-radiance field reconstruction of dynamic scenes from sparse calibrated RGB and RGBD cameras, temporal 3D form modeling using signed distance functions, and 2D video approximation. You can get the code, models, and collected data from GitHub.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.