Meet FLM-101B: An Open-Source Decoder-Only LLM With 101 Billion Parameters
Lately, Large language models (LLMs) are excelling in NLP and multimodal tasks but are facing two significant challenges: high computational costs and difficulties in conducting fair evaluations. These costs limit LLM development to a few major players, restricting research and applications. To address this, the paper introduces a growth strategy to significantly reduce LLM training expenses, emphasizing the need for cost-effective training methods in the field.
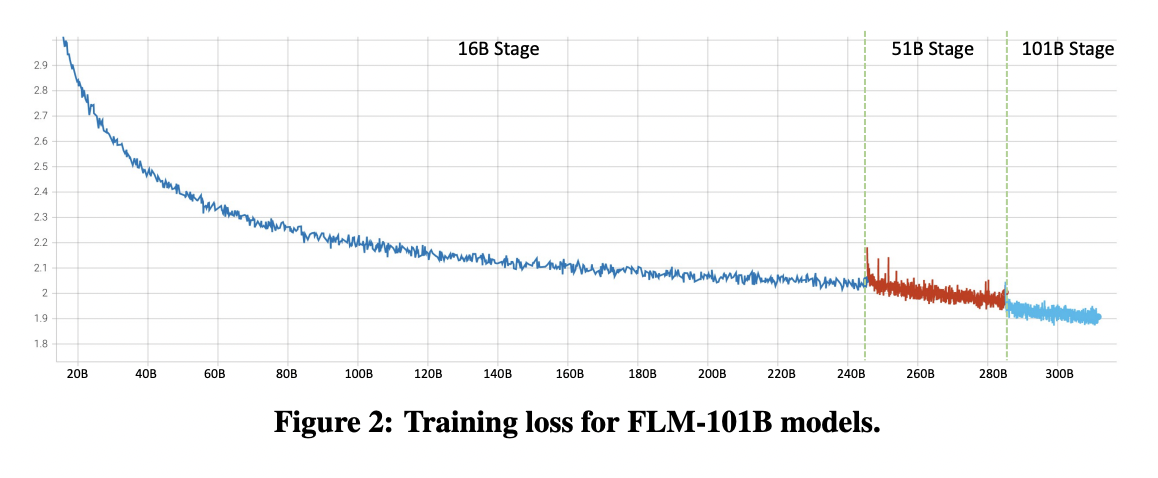
To address the training cost challenge, researchers train a 100B LLM by the growth strategy. Growth means that the number of parameters is not fixed in the training process but expands from a smaller size to a large ones. In order to assess the intelligence of Large Language Models (LLMs), researchers have developed a comprehensive IQ evaluation benchmark. This benchmark considers four crucial aspects of intelligence:
- Symbolic Mapping: LLMs are tested for their ability to generalize to new contexts using a symbolic mapping approach, similar to studies that use symbols instead of category labels.
- Rule Understanding: The benchmark evaluates whether LLMs can comprehend established rules and perform actions accordingly, a key aspect of human intelligence.
- Pattern Mining: LLMs are assessed for their capacity to recognize patterns through both inductive and deductive reasoning, reflecting the importance of pattern mining in various domains.
- Anti-Interference Ability: This metric measures LLMs’ capability to maintain performance in the presence of external noise, highlighting the core aspect of intelligence related to resistance to interference.
The main contributions of this study can be essentially summarised as:
- A pioneering achievement is the successful training of a Large Language Model (LLM) with over 100 billion parameters using a growth strategy from the ground up. Notably, this represents the most cost-effective approach to creating a 100B+ parameter model with a budget of only $100,000.
- The research addresses various instability issues in LLM training through enhancements in FreeLM training objectives, promising methods for hyperparameter optimization, and the introduction of function-preserving growth. These methodological improvements hold promise for the wider research community.
- Comprehensive experiments have been conducted, encompassing well-established knowledge-oriented benchmarks as well as a new systematic IQ evaluation benchmark. These experiments allow for a comparison of the model against robust baseline models, demonstrating the competitive and resilient performance of FLM-101B.
- The research team made significant contributions to the research community by releasing model checkpoints, code, related tools, and other resources. These assets are aimed at fostering further research in the domain of bilingual Chinese and English LLMs at the scale of 100 billion+ parameters.
Overall, this work not only demonstrates the feasibility of cost-effective LLM training but also contributes to a more robust framework for evaluating the intelligence of these models, ultimately propelling the field closer to the realisation of AGI.
Check out the Paper and Code. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.