Magnifying the Invisible: This Artificial Intelligence AI Method Uses NeRFs for Visualizing Subtle Motions in 3D
We live in a world full of motion, from the subtle movements of our bodies to the large-scale movements of the earth. However, many of these motions are too small to be seen with the naked eye. Computer vision techniques can be used to extract and magnify these subtle motions, making them easier to see and understand.
In recent years, neural radiance fields (NeRF) have emerged as a powerful tool for 3D scene reconstruction and rendering. NeRFs can be trained to represent the appearance of a 3D scene from a collection of images and can then be used to render the scene from any viewpoint.
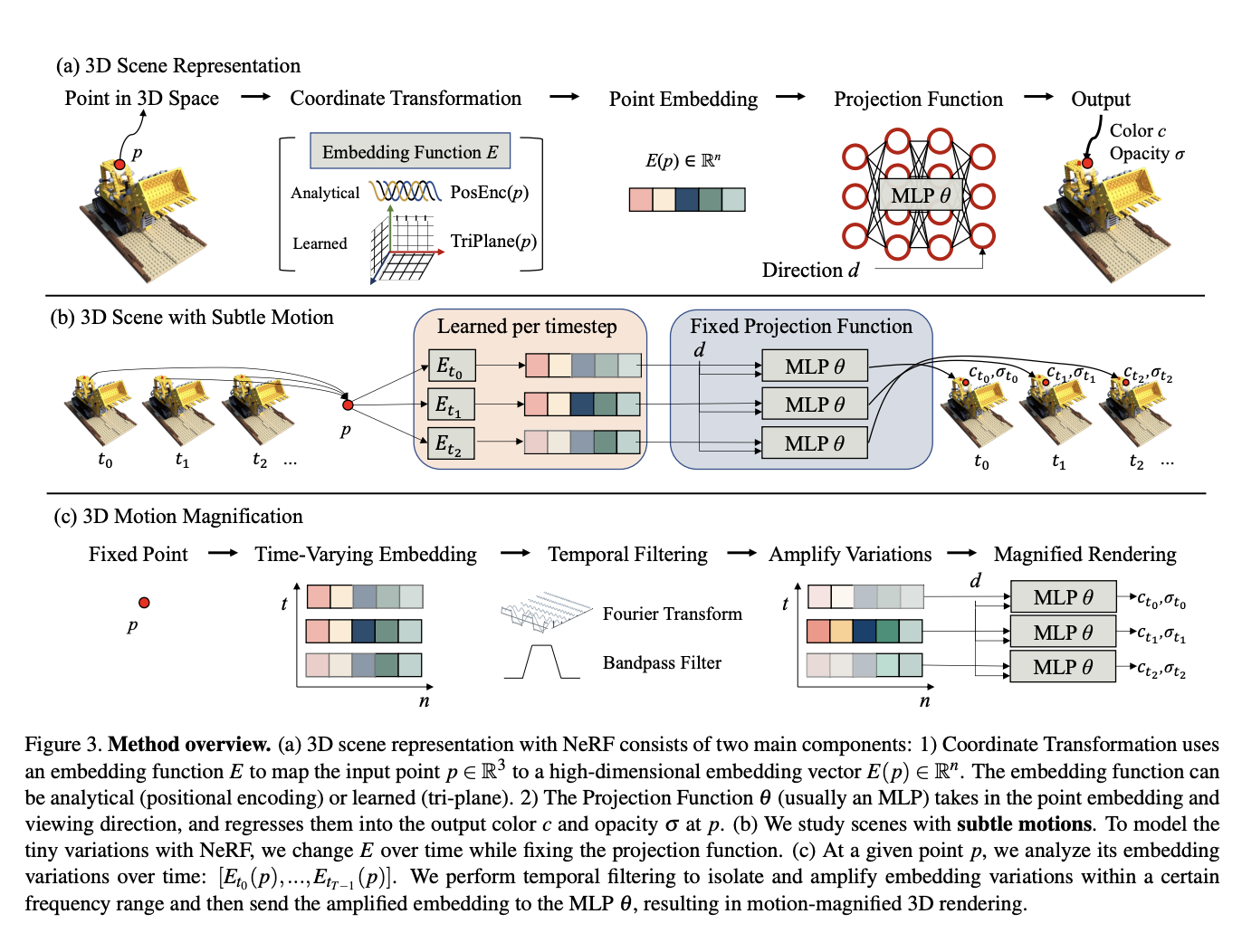
NeRFs represent the appearance of a 3D scene from a collection of images. NeRFs work by learning a function that maps from a 3D point to its corresponding color and radiance. This function can then be used to render the scene from any viewpoint. These models have been shown to be very effective at representing the appearance of complex 3D scenes. They have been used to render realistic 3D models of objects, scenes, and even people. NeRFs have also been used to develop new applications in virtual reality, augmented reality, and computer graphics.
What if we use the power of NeRFs to magnify the subtle motions in 3D scenes? This is not an easy task as it possesses a couple of challenges.
The first challenge is to collect a set of images of the scene with subtle motions. This can be difficult, as the motions must be small enough to be imperceptible to the naked eye, but large enough to be captured by the camera.
The second challenge is to train a NeRF to represent the appearance of the scene from the collected images. This can be a challenging task, as the NeRF must be able to learn the subtle temporal variations in the scene.
The third challenge is to perform Eulerian motion analysis on the NeRF’s point embeddings. This can be a computationally expensive task, as it requires analyzing the temporal variations in a high-dimensional space.
Let us meet with 3D motion magnification, which tackles all these challenges in a smart way.
3D motion magnification is an AI method that utilizes the power of NeRFs. It uses a NeRF to represent the scene with its subtle temporal variations. On top of the NeRF render, the Eulerian motion analysis is applied to amplify the temporal variations in the NeRF’s point embeddings. This results in a magnified 3D scene that reveals the subtle motions that were previously invisible.
This method has several key steps, the first one being data collection and NeRF training. It starts with collecting a set of images of the scene with subtle motions. The images should be captured from different viewpoints and at different time steps. Then, these collected images are used to train the NeRF model that is used to represent the appearance of the scene from the collected images. It is trained to minimize a loss function that measures the difference between the rendered images and the ground truth images.
Once the NeRF model is ready, the next step is to do Eulerian motion analysis. The temporal variations in the NeRF’s point embeddings are amplified using Eulerian motion analysis. It is a mathematical framework for analyzing the motion of fluids and solids. It can be used to extract the temporal variations in any time-varying field, such as the NeRF’s point embeddings. These amplified temporal variations are then used to magnify the motion in the scene, which is done by rendering the scene from the NeRF using the amplified point embeddings.
Check out the Paper, Project, and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.