Google Researchers Present a New Artificial Intelligence Approach to Modeling an Image-Space Prior to Scene Dynamics
Even seemingly motionless images include minute oscillations because of things like wind, water currents, breathing, or other natural rhythms. This is because the natural world is constantly in motion. Humans are especially sensitive to motion, which makes it one of the most prominent visual signals. Images taken without motion (or even with somewhat fanciful motion) sometimes feel unsettling or surreal. However, it is simple for people to comprehend or picture movement in a scene. Teaching a model to acquire realistic movement is more complex. The physical dynamics of a scene, or the forces acting on things due to their specific physical characteristics, such as their mass, elasticity, etc., produce the motion that people see in the outside world.
These forces and qualities are challenging to quantify and capture at scale, but thankfully, they frequently don’t need to be quantified since they may be caught and learned from the observed motion. Although this observable motion is multi-modal and based on intricate physical processes, it is frequently predictable: candles flicker in specific patterns, and trees sway and ruffle their leaves. They can imagine plausible motions that might have been in progress when the picture was taken or, if there may have been many possible such motions, a distribution of natural motions conditioned on that image by looking at a still image. This predictability is ingrained in their human perception of real scenes.
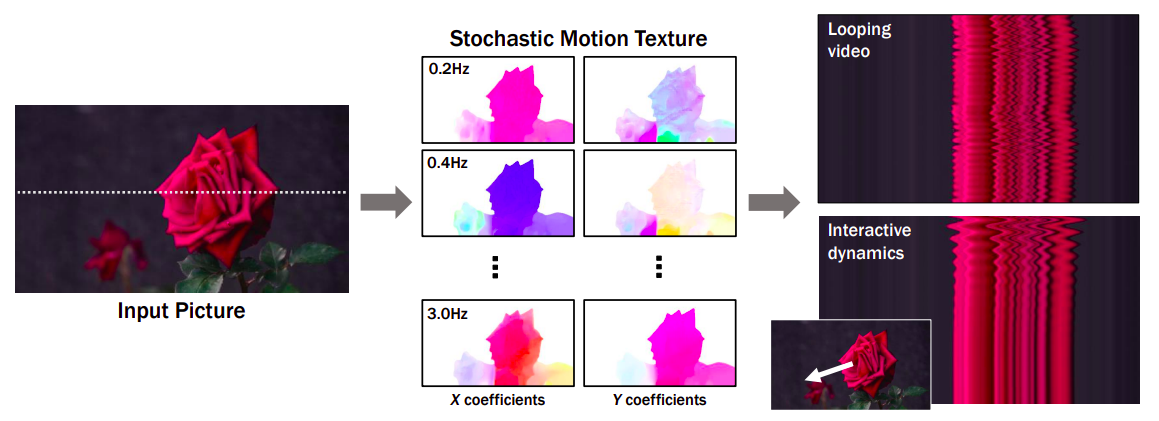
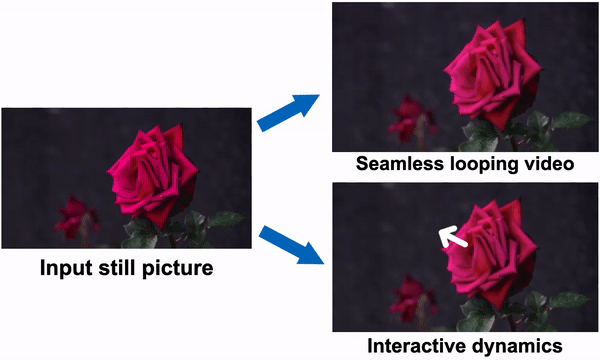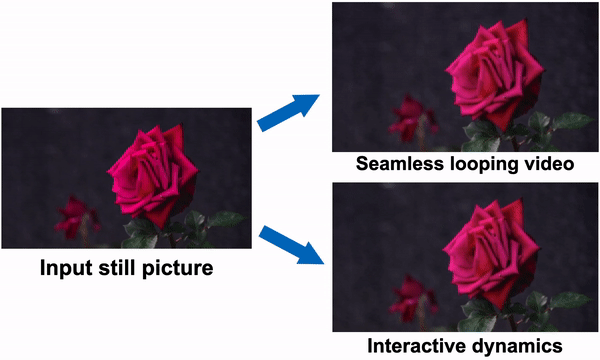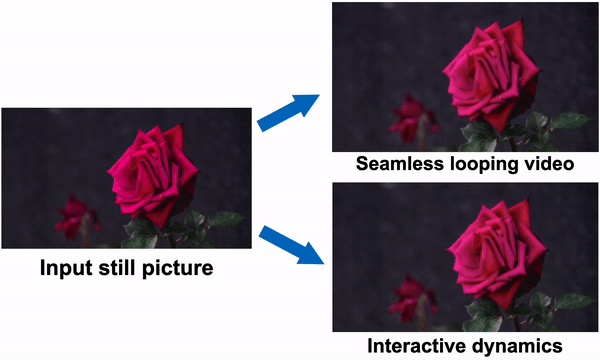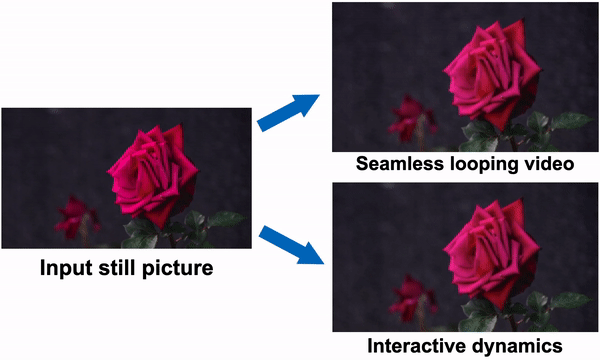
Figure 1: One can see how the method simulates a generative image-space prior to scene dynamics. Starting with a single RGB picture, the model creates a neural stochastic motion texture, a motion representation that simulates dense long-term motion trajectories in the Fourier domain. They demonstrate how their motion priors may be used for tasks like converting a single image into a movie that loops fluidly or mimicking object dynamics in response to interactive user stimulation (such as dragging and releasing an object’s point). They use space-time X-t slices over 10 seconds of video (along the scanline displayed in the input picture) to visualize the output films on the right.
To simulate this similar distribution digitally is a natural research subject, given how easily humans can visualize these potential movements. We have now been able to simulate extremely rich and complicated distributions, including distributions of real pictures conditioned on text, thanks to recent advancements in generative models, particularly conditional diffusion models. Numerous previously impractical applications, including the text-conditioned production of random, varied, and realistic visual material, have become viable because of this capacity. Recent research has demonstrated that modeling additional domains, such as videos and 3D geometry, may be equally beneficial for downstream applications in light of the success of these picture models.
In this paper, researchers from Google Research investigate the modeling of a generative prior for the motion of every pixel in a single image, also known as scene motion in image space. This model is trained using motion trajectories automatically retrieved from a sizable number of genuine video sequences. The trained model forecasts a neural stochastic motion texture based on an input picture, a collection of motion basis coefficients that describe the future trajectory of each pixel. They pick the Fourier series as their basis functions to confine their analysis to real-world sceneries with oscillating dynamics, such as trees and flowers moving in the wind. They forecast a neural stochastic motion texture using a diffusion model that produces coefficients for a single frequency at a time but coordinates these predictions across frequency bands.
As shown in Fig. 1, the generated frequency-space textures may be converted into dense, long-range pixel motion trajectories that synthesize upcoming frames with an image-based rendering diffusion model, converting static pictures into lifelike animations. Priors over motion capture have a more basic, lower-dimensional underlying structure than priors over raw RGB pixels, which more effectively explains fluctuations in pixel values. In contrast to earlier techniques that accomplish visual animation using raw video synthesis, their motion representation enables more coherent long-term production and finer-grained control over animations. Additionally, they show how their generated motion representation makes it easy to use for various downstream applications, including making videos that seamlessly loop, editing the induced motion, and enabling interactive dynamic images that simulate how an object would react to user-applied forces.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.