The Trick to Make LLaMa Fit into Your Pocket: Meet OmniQuant, an AI Method that Bridges the Efficiency and Performance of LLMs
Large language models (LLMs), like the infamous ChatGPT, have achieved impressive performance on a variety of natural language processing tasks, such as machine translation, text summarization, and question-answering. They have changed the way we communicate with computers and the way we do our tasks.
LLMs have emerged as transformative entities, pushing the boundaries of natural language understanding and generation. Among these, ChatGPT stands as a remarkable example, representing a class of LLMs designed to interact with users in conversational contexts. These models are the result of extensive training on extremely large text datasets. This gives them the ability to comprehend and generate human-like text.
However, these models are computationally and memory-intensive, which limits their practical deployment. As the name suggests, these models are large; when we mean large, we mean it. The most recent open-source LLM, LLaMa2 from Meta, contains around 70 billion parameters.
Reducing these requirements is an important step in making them more practical. Quantization is a promising technique to reduce the computational and memory overhead of LLMs. There are two main ways to do quantization – post-training quantization (PTQ) and quantization-aware training (QAT). While QAT offers competitive accuracy, it’s prohibitively expensive in terms of both computation and time. Therefore, PTQ has become the go-to method for many quantization efforts.
Existing PTQ techniques, like weight-only and weight-activation quantization, have achieved significant reductions in memory consumption and computational overhead. However, they tend to struggle with low-bit quantization, which is crucial for efficient deployment. This performance degradation in low-bit quantization is primarily due to the reliance on handcrafted quantization parameters, leading to suboptimal results.
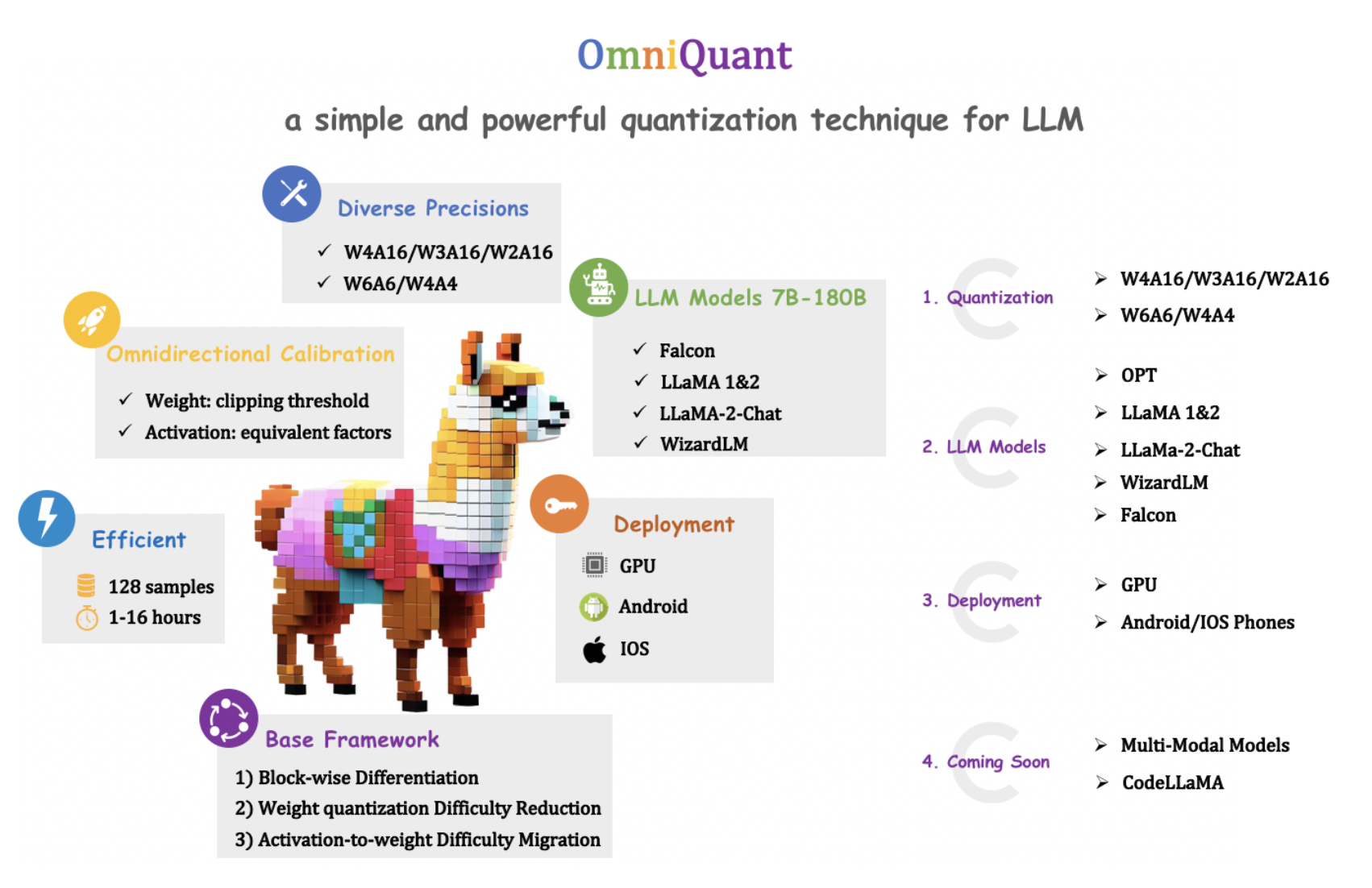
Let us meet with OmniQuant. It is a novel quantization technique for LLMs that achieves state-of-the-art performance across various quantization scenarios, particularly in low-bit settings, while preserving the time and data efficiency of PTQ.
OmniQuant takes a unique approach by freezing the original full-precision weights and incorporating a limited set of learnable quantization parameters. Unlike QAT, which involves cumbersome weight optimization, OmniQuant focuses on individual layers in a sequential quantization process. This allows for efficient optimization using simple algorithms.
OmniQuant consists of two crucial components – Learnable Weight Clipping (LWC) and Learnable Equivalent Transformation (LET). LWC optimizes the clipping threshold, modulating extreme weight values, while LET tackles activation outliers by learning equivalent transformations within a transformer encoder. These components make full-precision weights and activations more amenable to quantization.
The flexibility of OmniQuant shines through its versatility, catering to both weight-only and weight-activation quantization. The best part is that OmniQuant introduces no additional computational burden or parameters for the quantized model, as the quantization parameters can be fused into the quantized weights.
Instead of jointly optimizing all parameters across the LLM, OmniQuant sequentially quantifies the parameters of one layer before moving on to the next. This allows OmniQuant to be optimized efficiently using a simple stochastic gradient descent (SGD) algorithm.
It is a practical model as it’s quite easy to implement even on a single GPU. You can train your own LLM in 16 hours, which makes them really accessible in various real-world applications. Also, you do not sacrifice performance as OmniQuant outperforms previous PTQ-based methods.
Though, it is still a relatively new method, and there are some limitations to its performance. For example, it can sometimes produce slightly worse results than full-precision models. However, this is a minor inconvenience of OmniQuant as it is still a promising technique for the efficient deployment of LLMs.
Check out the Paper and Github link. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.