Researchers from UCI and Zhejiang University Introduce Lossless Large Language Model Acceleration via Self-Speculative Decoding Using Drafting And Verifying Stages
Large Language Models (LLMs) based on transformers, such as GPT, PaLM, and LLaMA, have become widely used in a variety of real-world applications. These models have been applied to a variety of tasks, including text production, translation, and natural language interpretation. However, these models’ high inference costs, particularly in situations where low latency is important, are a major concern. The autoregressive decoding method used by these models is the main cause of the high inference costs. Since each output token is produced sequentially during autoregressive decoding, there are a lot of Transformer calls. The memory bandwidth of each Transformer call is limited, leading to inefficient computation and prolonged execution times.
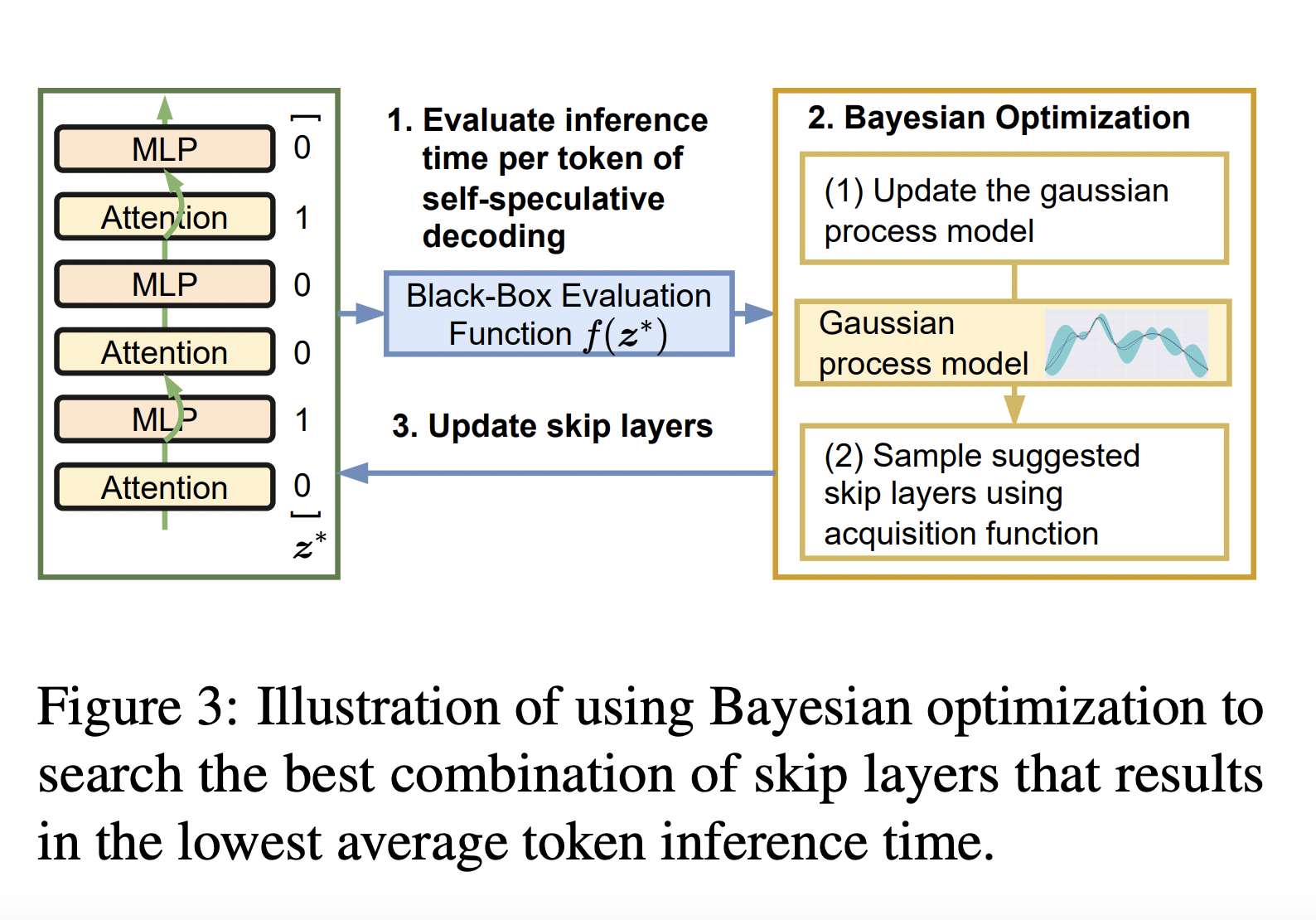
In order to speed up the inference process of Large Language Models (LLMs), a recent study has introduced a unique method called self-speculative decoding that does not require an auxiliary model. This approach tackles the problem of producing the inference more quickly while preserving output quality. It is characterized by a two-stage procedure that combines drafting and verification.
- Drafting Stage – The objective of the drafting stage is to produce draught tokens more quickly, even if they are marginally of worse quality than tokens produced using the conventional autoregressive method. The method bypasses some intermediary layers during drafting to accomplish this. These intermediary layers in LLMs often refine the output, but they also take up a lot of time and resources during inference.
- Verification Stage: The technique generates the draught output tokens in the drafting stage and then validates them in a single forward pass using the original, unaltered LLM. Using the conventional autoregressive decoding technique, the LLM would have produced the same end result, which is ensured by this verification step. Because of this, even if the drafting stage generated tokens more quickly, the end product’s quality is preserved.
Self-speculative decoding does not require further neural network training, which is one of its main advantages. Training auxiliary models or making significant changes to the LLM’s architecture, which can be challenging and resource-intensive, are common components of existing methods for faster inference. Self-speculative decoding, on the other hand, is a “plug-and-play” approach that can be added to existing LLMs without additional training or model alterations.
The research has offered empirical support for self-speculative decoding’s efficacy. The benchmark results are shown using LLaMA-2 and its improved models. Based on these benchmarks, the self-speculative decoding method can decode data up to 1.73 times faster than the conventional autoregressive method. This has the important benefit of making the inference process approximately twice as quick while preserving output quality, which is important in situations when latency is an issue.
In conclusion, self-speculative decoding is a revolutionary method that enhances how Large Language Models infer information. It accomplishes this by establishing a two-step process of drafting and verification, choosing which layers to skip during the drafting stage to generate tokens more quickly, and verifying the output quality during the verification stage. This method speeds up LLM inference without adding any extra memory burden or training requirements for neural networks.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.