Researchers from the University of Oregon and Adobe Introduce CulturaX: A Multilingual Dataset with 6.3T Tokens in 167 Languages Tailored for Large Language Model (LLM) Development
By dramatically improving state-of-the-art performance across a wide range of tasks and revealing new emergent skills, large language models (LLMs) have profoundly impacted NLP research and applications. To encode input texts into representation vectors, the encoder-only models have been investigated; to create texts, the decoder-only models have been studied; and to accomplish sequence-to-sequence creation, the encoder-decoder models have been studied. The exponential growth in model sizes and training datasets, both required by the scaling laws for maximum performance, has been the primary force behind the remarkable capabilities of LLMs. For example, although the BERT model only contained a few hundred million parameters, more contemporary GPT-based models now include hundreds of billions of parameters.
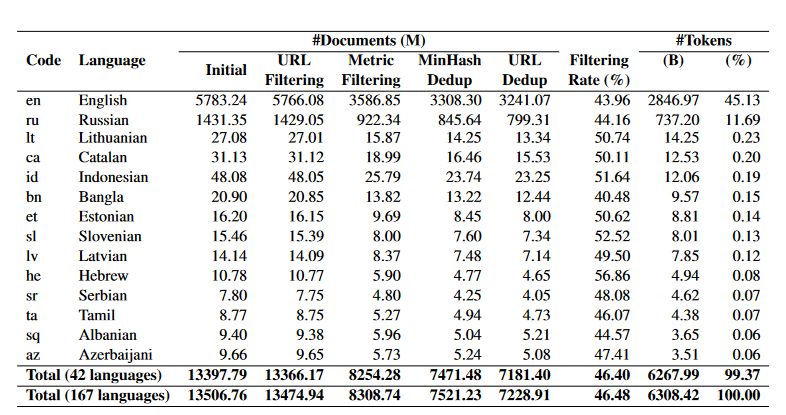
Massive model sizes and huge training datasets are the primary elements in advancing large language models (LLMs) with amazing learning capabilities. With the development of NLP, LLMs have been increasingly available to the general public to encourage further study and practical applications. However, training datasets for these LLMs are typically only partially provided, especially for the most recent state-of-the-art models. Extensive data cleaning and deduplication are required to create high-quality training data for LLMs. In this way, the need for more openness around training data has stymied efforts to replicate findings and progress the field of hallucination and bias research in LLMs. These difficulties are compounded in multilingual learning scenarios by the typically insufficient collection and cleaning of multilingual text collections. As a result, there isn’t a good open-source dataset that can be used for training LLMs across languages. CulturaX, a massive multilingual dataset including 6.3 trillion tokens in 167 languages, was developed by a collaboration of academics at the University of Oregon and Adobe Research to address this problem. To ensure the highest quality for model training, the dataset goes through a stringent pipeline comprising numerous steps of cleaning and deduplication. These processes include identifying the languages in the dataset, filtering the dataset using URLs, cleaning the dataset using metrics, refining the documents, and deduplicating the data.
CulturaX undergoes thorough document-level cleaning and deduplication to ensure the highest quality training LLMs across languages. The data cleaning procedure uses a complete pipeline to eliminate inaccurate information. This necessitates the elimination of distractions such as inaccurate language identification, poisonous data, and non-linguistic material.
Key Features
- CulturaX is the largest open-source, multilingual dataset that has ever been thoroughly cleaned and deduplicated for use in LLM and NLP applications.
- CulturaX provides a multilingual, open-source, and massive dataset with immediately applicable and high-quality data to train LLMs, solving many problems with current datasets.
- While there exist multilingual open-source datasets with text data in various languages, such as mC4, their quality, and scale do not fulfill the requirements for efficiently training LLMs, especially generative models such as GPT. For instance, as mentioned in the introduction, neither mC4 nor OSCAR provides document-level fuzzy deduplication. The usage of cld3 results in inferior language recognition for mC4, which is another drawback. While CC100 does contain data past 2018, BigScience ROOTS only gives a sampling of the data for 46 languages.
HuggingFace’s full public release of CulturaX will help further study multilingual LLMs and their applications. Check out here https://huggingface.co/datasets/uonlp/CulturaX
You should check out CulturaX, a new multilingual dataset with text data for 167 languages. A thorough workflow cleans and removes duplicates from the dataset, resulting in 6.3 trillion tokens. As a huge, high-quality dataset, CulturaX may be utilized to train effective LLMs in various languages easily. This information is freely available to the public, and researchers hope it may inspire further studies and practical uses of language acquisition.
Check out the Paper and Dataset. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.