This AI Research Proposes LayoutNUWA: An AI Model that Treats Layout Generation as a Code Generation Task to Enhance Semantic Information and Harnesses the Hidden Layout Expertise of Large Language Models (LLMs)
With the growth of LLMs, there has been thorough research on all aspects of LLMs. So, there have been studies on graphic layout, too. Graphic layout, or how design elements are arranged and placed, significantly impacts how users interact with and perceive the information given. A new field of inquiry is layout generation. It aims to provide various realistic layouts that simplify developing objects.
Present-day methods for layout creation mainly perform numerical optimization, focusing on the quantitative aspects while ignoring the semantic information of the layout, such as the connections between each layout component. However, because it focuses largely on collecting the quantitative elements of the layout, such as positions and sizes, and leaves out semantic information, such as the attribute of each numerical value, this method might need to be able to express layouts as numerical tuples.
Since layouts feature logical links between their pieces, programming languages are a viable option for layouts. We can develop an organized sequence to describe each layout using code languages. These programming languages can combine logical concepts with information and meaning, bridging the gap between current approaches and the demand for more thorough representation.
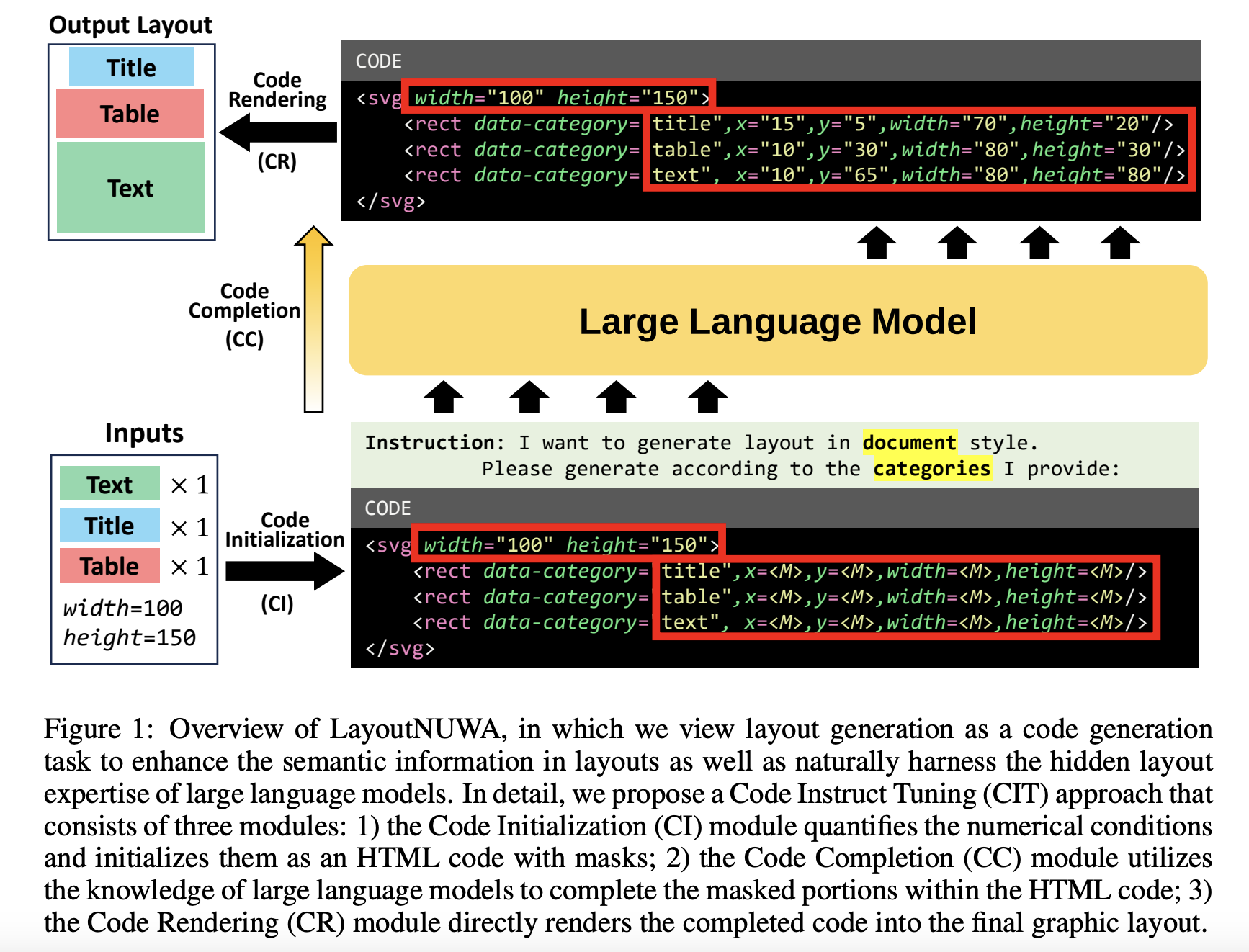
As a result, the researchers developed LayoutNUWA. This first model approaches layout development as a code generation problem to improve semantic information and tap into large language models’ (LLMs’) hidden layout expertise.
Code Instruct Tuning (CIT) is made up of three interconnected components. The Code Initialization (CI) module quantifies numerical circumstances before converting them into HTML code. This HTML code contains masks placed in specific locations to improve the layouts’ readability and cohesion. Second, to fill in the masked areas of the HTML code, the Code Completion (CC) module uses the formatting know-how of Large Language Models (LLMs). To improve the precision and consistency of the generated layouts, this uses LLMs. Finally, the Code Rendering (CR) module renders the code into the final layout output. To improve the precision and consistency of the generated layouts, this uses LLMs.
Magazine, PubLayNet, and RICO were three frequently used public datasets to assess the model’s performance. The RICO dataset, which includes approximately 66,000 UI layouts and divides them into 25 element kinds, focuses on user interface design for mobile applications. On the other hand, PubLayNet provides a sizable library of more than 360,000 layouts across numerous documents, categorized into five-element groups. A low-resource resource for magazine layout research, the Magazine dataset comprises over 4,000 annotated layouts divided into six primary element classes. All three datasets were preprocessed and tweaked for consistency using the LayoutDM framework. To do this, the original validation dataset was designated as the testing set, layouts with more than 25 components were filtered away, and the refined dataset was split into training and new validation sets, with 95% of the dataset going to the former and 5% to the latter.
They conducted experiments using code and numerical representations to evaluate the model’s results thoroughly. They developed a Code Infilling task specifically for the numerical output format. Instead of predicting the complete code sequence in this job, the Large Language Model (LLM) was asked to predict only the hidden values within the number sequence. The findings showed that model performance significantly decreased when generated in the numerical format, along with a rise in the failure rate of model development attempts. For example, this method produced repetitious outcomes in some cases. This decreased efficiency can be attributed to the conditional layout generation task’s goal of creating coherent layouts.
The researchers also said that separate and illogical numbers can be produced if attention is only paid to forecasting the masked bits. Additionally, this trend may increase the chance that a model fails to generate data, especially when indicating layouts with more concealed values.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.