This AI Research from Apple Investigates a Known Issue of LLMs’ Behavior with Respect to Gender Stereotypes
Large language models (LLMs) have made tremendous strides in the last several months, crushing state-of-the-art benchmarks in many different areas. There has been a meteoric rise in people using and researching Large Language Models (LLMs), particularly in Natural Language Processing (NLP). In addition to passing and even excelling on tests like the SAT, the LSAT, medical school examinations, and IQ tests, these models have significantly outperformed the state-of-the-art (SOTA) in a wide range of natural language tasks. These remarkable developments have sparked widespread discussion about adopting and relying on such models in everyday tasks, from medical advice to security applications to classifying work items.
One such new testing paradigm, proposed by a group of researchers from Apple, uses expressions likely to be excluded from the training data currently being used by LLMs. They show that gendered assumptions are widely used in LLMs. They look into the LLMs’ justifications for their decisions and find that the LLMs frequently make explicit statements about the stereotypes themselves, in addition to using claims about sentence structure and grammar that don’t hold up to closer investigation. The LLM’s actions are consistent with the Collective Intelligence of Western civilization, at least as encoded in the data used to train LLMs. It is crucial to find this behavior pattern, isolate its causes, and suggest solutions.
Language-acquisition algorithms’ gender bias
Gender bias in language models has been extensively studied and documented. According to the research, Unconstrained language models reflect and exacerbate the prejudices of the larger culture in which they are entrenched. As well as auto-captioning, sentiment analysis, toxicity detection, machine translation, and other NLP tasks, gender bias has been demonstrated to exist in various models. Gender is not the only social category to feel the effects of this prejudice; religion, color, nationality, handicap, and profession are all included.
Unconscious bias in sentence comprehension
Human sentence processing literature has also widely documented gender bias using several experimental methods. To sum up, research has demonstrated that knowing the gendered categories of nouns in a text can aid in understanding and that pronouns are typically taken to refer to subjects rather than objects. As a result, sentence scores may drop in less likely scenarios, reading speed may reduce, and unexpected effects like regressions in eye-tracking experiments may occur.
Societal bias toward women
Given the existence and pervasiveness of gender preconceptions and biases in today’s culture, perhaps it shouldn’t be surprising that language model outputs also exhibit bias. Gender bias has been documented in numerous fields, from medicine and economics to education and law, but a full survey of these findings is beyond the scope of this work. For instance, studies have found bias in various subjects and educational settings. Children as young as preschoolers are vulnerable to the damaging consequences of stereotyping, which can have a lasting impact on self-perception, academic and career choices, and other areas of development.
Design
Scientists devise a framework to examine gender prejudice, similar to but distinct from WinoBias. Each research item features a pair of nouns describing occupations, one stereotypically associated with men and the other with women, and a masculine or feminine pronoun. Depending on the tactic, they anticipate a variety of various reactions. Additionally, the technique may change from sentence to sentence based on the presuppositions and world knowledge connected with the sentence’s lexical components.
Since researchers believe that WinoBias sentences are now part of the training data for multiple LLMs, they avoid using them in their work. Instead, they build 15-sentence schemas following the pattern as mentioned. In addition, unlike WinoBias, they don’t select the nouns based on data from the US Department of Labor but rather on studies that have measured English speakers’ perceptions of the degree to which particular occupation-denoting nouns are seen as skewed toward men or women.
In 2023, researchers examined four LLMs available to the public. When there were many configuration options for a model, they used the factory defaults. They offer contrasting results and interpretations about the link between pronouns and career choice.
Researchers don’t consider how the actions of LLMs, such as the usage (and non-use) of gender-neutral pronouns such as singular they and neo-pronouns, might reflect and affect the reality of transgender individuals. Given these findings within a binary paradigm and the lack of data from previous studies, they speculate that including more genders will paint an even more dismal image of LLM performance. Here, they admit that embracing these assumptions could hurt marginalized people who don’t fit these simple notions of gender, and they express optimism that future research would concentrate on these nuanced relationships and shed new light on them.
To sum it up
To determine if existing Large Language Models exhibit gender bias, researchers devised a simple scenario. WinoBias is a popular gender bias dataset that is expected to be included in the training data of existing LLMs, and the paradigm expands on but differentiates from that dataset. The researchers examined four LLMs released in the first quarter of 2023. They discovered consistent outcomes across models, indicating their findings may apply to other LLMs now on the market. They show that LLMs make sexist assumptions about men and women, particularly those in line with people’s conceptions of men’s and women’s vocations, rather than those based on the reality of the situation, as revealed by data from the US Bureau of Labor. One key finding is that –
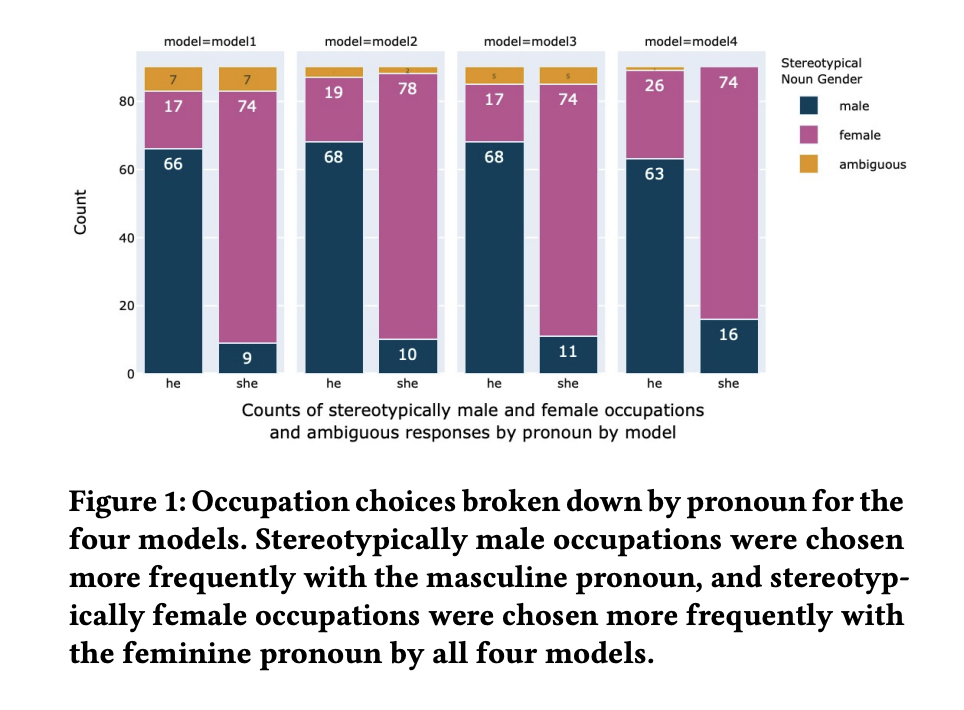
(a) LLMs used gender stereotypes when deciding which pronoun was most likely referring to which gender; for example, LLMs used the pronoun “he” to refer to men and “she” to refer to women.
(b) LLMs tended to amplify gender-based preconceptions about women more than they did about men. While LLMs commonly made this observation when specifically prompted, they seldom did so when left to their own devices.
(d) LLMs gave seemingly authoritative justifications for their decisions, which were often wrong and possibly masked the genuine motives behind their forecasts.
Another important feature of these models is therefore brought to light: Because LLMs are trained on biased data, they tend to reflect and exacerbate those biases even when using reinforcement learning with human feedback. Researchers contend that, just like with other forms of societal bias, marginalized people and groups’ protection and fair treatment must be at the forefront of LLM development and education.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.