Researchers from MIT and CUHK Propose LongLoRA (Long Low-Rank Adaptation), An Efficient Fine-Tuning AI Approach For Long Context Large Language Models (LLMs)
The introduction of Large language models (LLMs) has brought a significant level of advancement in the field of Artificial Intelligence. Based on the concepts of Natural Language Processing (NLP), Natural Language Understanding (NLU), and Natural Language Generation (NLG), LLMs have taken over the world with their incredible capabilities. The well-known models, such as LLaMA and LLaMA2, have been very effective tools for understanding and producing natural language.
However, they have set restrictions, such as a maximum context size of 2048 tokens for LLaMA and 4096 tokens for LLaMA2, respectively. Due to this restriction, they struggle to execute duties that call for digesting lengthy documents or lengthy queries. Training or perfecting LLMs with longer sequences is one method for extending the context window, but this presents computing difficulties and may be resource-prohibitively expensive.
Low-rank adaptation (LoRA) is an easy method for extending the context window. Low-rank matrices, which are computationally efficient and limit the number of trainable parameters, are used by LoRA to alter the linear projection layers in self-attention blocks. However, the training of long-context models with simple low-rank adaptation does not appear to be very effective, according to empirical studies. Due to the typical self-attention mechanism, it produces significant levels of confusion for extended context expansions and loses effectiveness as the context size increases.
To overcome the limitations, a team of researchers has introduced LongLoRA, an efficient fine-tuning approach for extending the context sizes of pre-trained large language models without incurring excessive computational costs. LongLoRA has been developed for effectively increasing the context window of pretrained LLMs like LLaMA2. It accelerates the process of expanding the context of LLMs in two important ways.
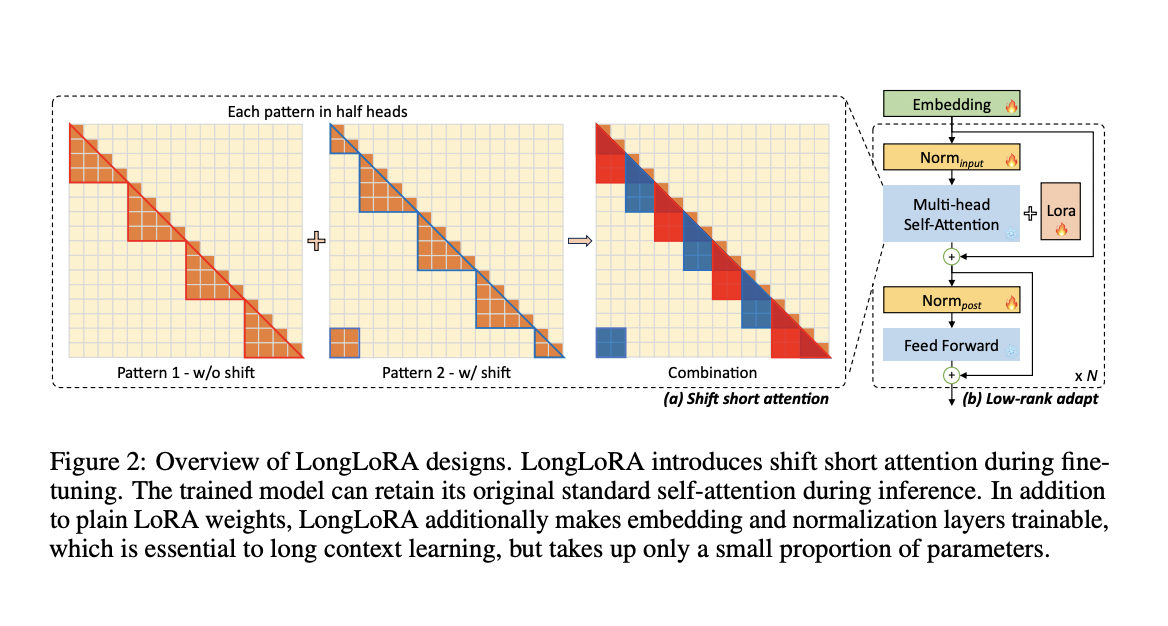
First, LongLoRA makes effective context extension during fine-tuning possible by utilizing shift short attention (S2-Attn). While dense global attention is still required for LLMs to perform well during inference, the fine-tuning process can be carried out effectively and quickly by employing sparse local attention. In comparison to fine-tuning with conventional attention techniques, S2-Attn enables context extension and results in significant computational savings, as it can be easily integrated and is an optional part of inference because it just requires two lines of code to implement during training.
Second, LongLoRA reconsiders the fine-tuning procedure with an emphasis on parameter-effective context expansion techniques. The team has discovered that LoRA performs admirably for context extension, provided the model has trainable embedding and normalization layers. This realization is key to successfully extending the context without substantially increasing the computing burden.
With LLaMA2 models ranging in size from 7B/13B to 70B, LongLoRA has presented remarkable empirical results for a variety of tasks. On a single 8 x A100 GPU computer, the method increases the context of these models from 4k tokens to 100k tokens for LLaMA2 7B or up to 32k tokens for LLaMA2 70B. It does this expanded context while maintaining the original model structures, making it compatible with already-in-use methods and tools like FlashAttention-2.
A dataset called LongQA has also been developed for supervised fine-tuning in order to assist the actual use of LongLoRA. More than 3k question-answer pairings with extensive contexts can be found in this dataset. The availability of this dataset expands LongLoRA’s usefulness for academics and professionals looking to expand the capabilities of LLMs.
Check out the Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.