Researchers from the University of Washington and Google have Developed Distilling Step-by-Step Technology to Train a Dedicated Small Machine Learning Model with Less Data
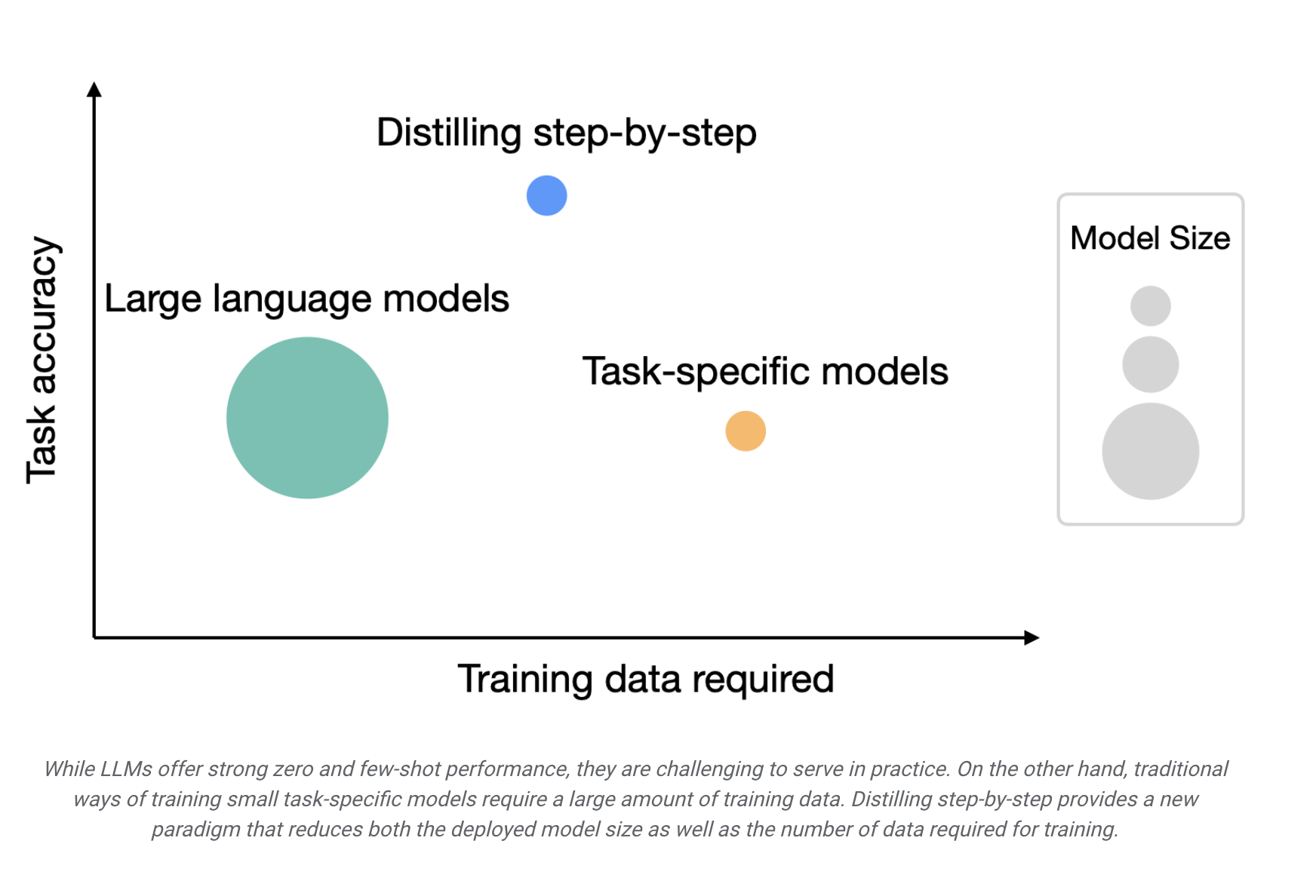
In recent years, large language models (LLMs) have revolutionized the field of natural language processing, enabling unprecedented zero-shot and few-shot learning capabilities. However, their deployment in real-world applications has been hindered by their immense computational demands. A single 175 billion parameter LLM necessitates a staggering 350GB of GPU memory and specialized infrastructure. With today’s state-of-the-art models boasting over 500 billion parameters, these requirements render LLMs inaccessible to many research teams, particularly those with low-latency performance needs.
To address this deployment challenge, researchers have turned to smaller specialized models, trained through either fine-tuning or distillation. Fine-tuning, while effective, relies on costly and time-consuming human-generated labels. Distillation, on the other hand, demands copious amounts of unlabeled data, which can be difficult to obtain.
In a groundbreaking study by a research team from Google and the University of Washington presented at ACL2023, the authors introduced “Distilling Step-by-Step,” a novel mechanism designed to mitigate the trade-off between model size and the cost of data collection. This innovative approach hinges on extracting informative natural language rationales, or intermediate reasoning steps, from LLMs. These rationales serve as additional, richer supervision in training smaller task-specific models alongside standard task labels.
The researchers outline a two-stage process for implementing Distilling Step-by-Step. First, they employ CoT prompting to extract rationales from an LLM, enabling the model to generate rationales for unseen inputs. Subsequently, these rationales are integrated into the training of small models using a multi-task learning framework, with task prefixes guiding the model’s differentiation between label prediction and rationale generation.
In a series of experiments, a 540B parameter LLM was utilized, along with T5 models for task-specific downstream tasks. Distilling Step-by-Step exhibited remarkable performance gains with significantly reduced data requirements. For instance, on the e-SNLI dataset, the method outperformed standard fine-tuning with just 12.5% of the full dataset. Similar reductions in dataset size were observed across various NLP tasks, including ANLI, CQA, and SVAMP.
Furthermore, Distilling Step-by-Step achieved superior performance using considerably smaller model sizes compared to few-shot CoT-prompted LLMs. For instance, on the e-SNLI dataset, a 220M T5 model surpassed the performance of a 540B PaLM. On ANLI, a 770M T5 model outperformed a 540B PaLM by over 700 times, demonstrating the immense potential for efficiency gains.
Notably, Distilling Step-by-Step showcased its ability to outperform few-shot LLMs using significantly smaller models and less data. For instance, on ANLI, a 770M T5 model surpassed the performance of a 540B PaLM using only 80% of the full dataset, a feat unattainable through standard fine-tuning.
In conclusion, Distilling Step-by-Step presents a groundbreaking paradigm for training small, task-specific models. By extracting rationales from LLMs, this approach not only reduces the data required for model training but also enables the use of significantly smaller models. This innovative technique stands to revolutionize the field of natural language processing, making advanced language models more accessible and practical for a broader range of applications.
Check out the Paper and Google AI Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.