Google DeepMind Researchers Uncover Scalable Solutions to Combat Training Instabilities in Transformer Models: An In-depth Analysis on Smaller Scale Reproducibility and Optimization Strategies
An innovative advancement in the domain of Artificial Intelligence is scaling up Transformers. It has made major advancements possible in a number of applications, including chat models and image production. Though transformer models have significantly gained a lot of popularity and attention from the masses and the AI community, not all attempts at training huge Transformers are successful. Researchers have been continuously discovering instabilities that might obstruct or interrupt the learning process.
As the computing resources needed for extensive Transformer training continue to rise, it is critical to comprehend how and why Transformer training can go wrong. Teams commonly experience training instabilities when working on training big Transformer-based models, especially when working at a large scale, which does not happen when using the same training settings for smaller models.
In a recent study, a team of researchers from Google DeepMind has developed techniques for simulating and examining training stability and instability in smaller-scale models. The study initially focuses on two well-established causes of training instability that have been identified in other investigations. The first is the growth of logits in attention layers, and the second is the divergence of output logits from the log probabilities.
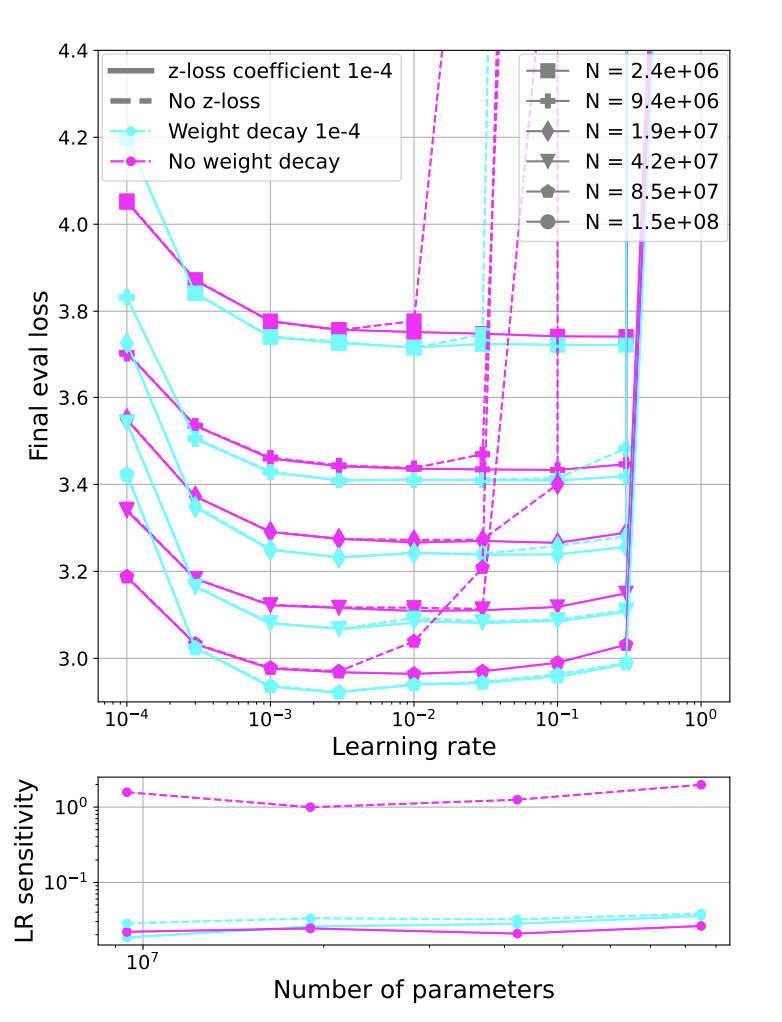
By examining the relationship between the learning rate and the loss during training at different scales, the researchers have discovered that these instabilities also manifest in smaller models, especially when high learning rates are used. They have also found that the previously used methods to lessen these instabilities in large-scale models work just as well in smaller models with similar problems.
This prompts the researchers to investigate how other widely used methods and interventions—which are frequently used to enhance models and training—affect the final loss’s sensitivity to variations in the learning rate by looking into techniques like warm-up, µParam, and weight decay. The researchers are able to train smaller models with constant losses using a combination of these strategies, even when learning rates vary across multiple orders of magnitude.
The team’s research has come to a close with two situations where it was able to identify instabilities before they became an issue. They have done this by examining how the model’s gradient norms and activation patterns change as the model scales. This predictive feature offers insightful information for monitoring and resolving prospective training problems earlier.
In conclusion, this study investigates the phenomenon at smaller sizes in order to address the problem of training instability in large Transformer-based models. The researchers wanted to gain a deeper knowledge of the variables that affect training stability. To this end, they are researching known instabilities and the effects of different optimization strategies. They also investigate predictive techniques based on model behavior, which may aid in avoiding instability problems in the first place.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.