This Research Paper Introduces Lavie: High-Quality Video Generation with Cascaded Latent Diffusion Models
In recent years, Diffusion Models (DMs) have made significant strides in the realm of image synthesis. This has led to a heightened focus on generating photorealistic images from text descriptions (T2I). Building upon the accomplishments of T2I models, there has been a growing interest among researchers in extending these techniques to the synthesis of videos controlled by text inputs (T2V). This expansion is driven by the anticipated applications of T2V models in domains such as filmmaking, video games, and artistic creation.
Achieving the right balance between video quality, training cost, and model compositionality remains a complex task, necessitating careful considerations in model architecture, training strategies, and the collection of high-quality text-video datasets.
In response to these challenges, a new integrated video generation framework called LaVie has been introduced. This framework, boasting a total of 3 billion parameters, operates using cascaded video latent diffusion models. LaVie serves as a foundational text-to-video model built upon a pre-trained T2I model (specifically, Stable Diffusion, as presented by Rombach et al., 2022). Its primary goal is to synthesize visually realistic and temporally coherent videos while retaining the creative generation capabilities of the pre-trained T2I model.

Figure 1 above demonstrates Text-to-video samples and Figure 2 demonstrates Diverse video generation results by Lavie.

LaVie incorporates two key insights into its design. First, it utilizes simple temporal self-attention coupled with RoPE to effectively capture inherent temporal correlations in video data. Complex architectural modifications provide only marginal improvements in the generated results. Second, LaVie employs joint image-video fine-tuning, which is essential for producing high-quality and creative outcomes. Attempting to fine-tune directly on video datasets can compromise the model’s ability to mix concepts and lead to catastrophic forgetting. Joint image-video fine-tuning facilitates large-scale knowledge transfer from images to videos, encompassing scenes, styles, and characters.
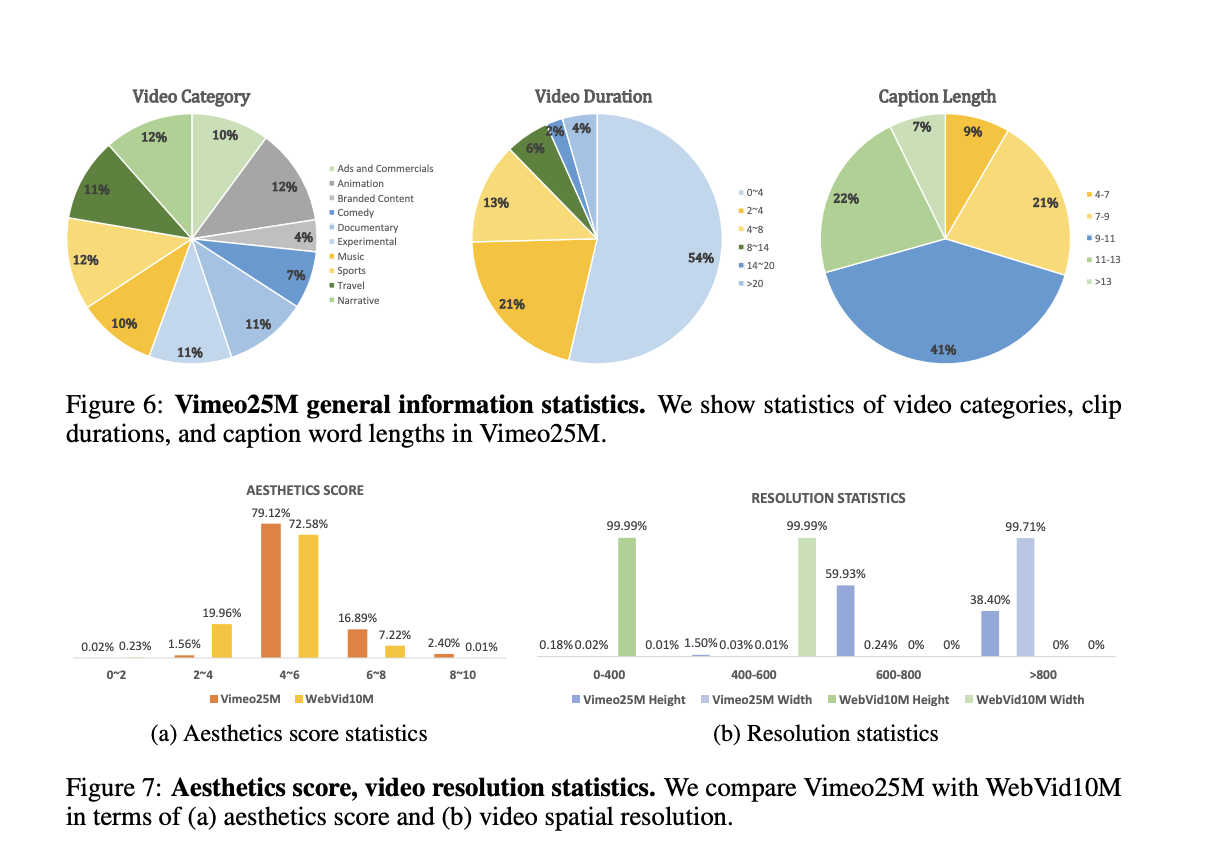
Additionally, the publicly available text-video dataset, WebVid10M, is found to be inadequate for supporting the T2V task due to its low resolution and focus on watermark-centered videos. In response, LaVie benefits from a newly introduced text-video dataset named Vimeo25M, which comprises 25 million high-resolution videos (> 720p) accompanied by text descriptions.
Experiments demonstrate that training on Vimeo25M significantly enhances LaVie’s performance, allowing it to generate superior results in terms of quality, diversity, and aesthetic appeal. Researchers envision LaVie as an initial step towards achieving high-quality T2V generation. Future research directions involve expanding the capabilities of LaVie to synthesize longer videos with intricate transitions and movie-level quality based on script descriptions.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.

Credit: Source link
Comments are closed.