Salesforce AI Introduces GlueGen: Revolutionizing Text-to-Image Models with Efficient Encoder Upgrades and Multimodal Capabilities
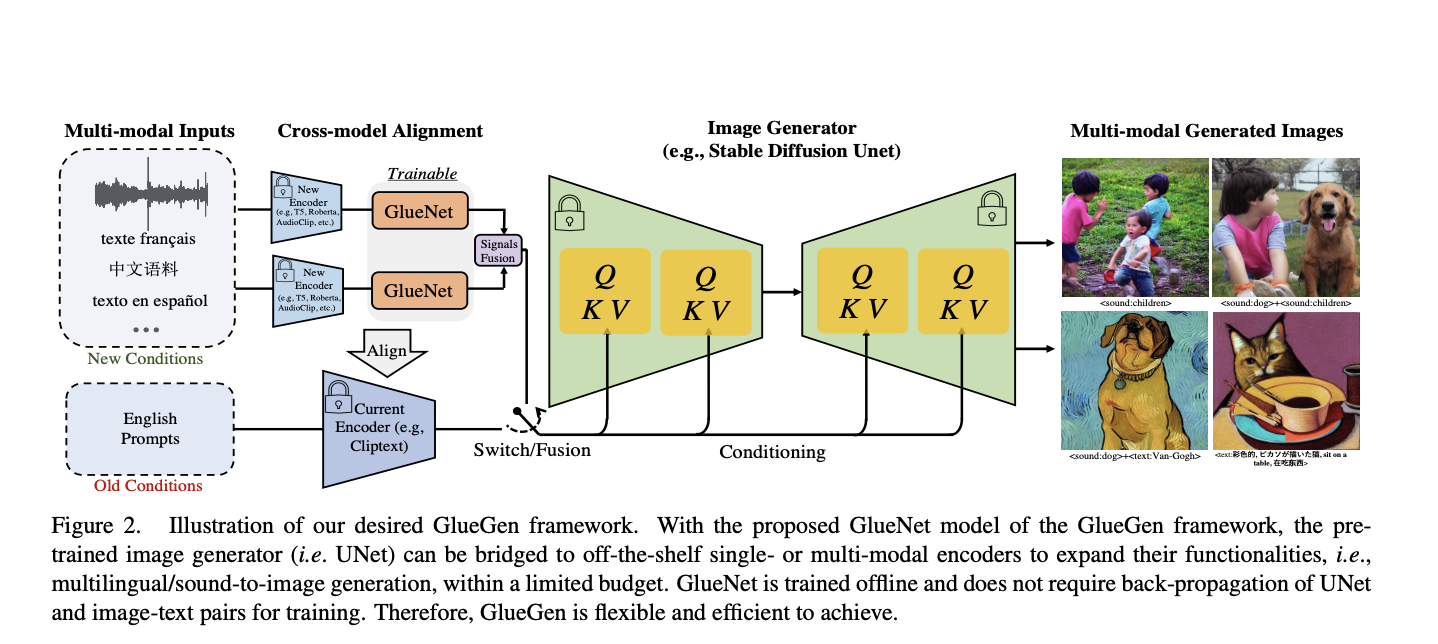
In the rapidly evolving landscape of text-to-image (T2I) models, a new frontier is emerging with the introduction of GlueGen. T2I models have demonstrated impressive capabilities in generating images from text descriptions, but their rigidity in terms of modifying or enhancing their functionality has been a significant challenge. GlueGen aims to change this paradigm by aligning single-modal or multimodal encoders with existing T2I models. This approach by researchers from Northwestern University, Salesforce AI Research, and Stanford University simplifies upgrades and expansions and ushers in a new era of multi-language support, sound-to-image generation, and enhanced text encoding. In this article, we will delve into the transformative potential of GlueGen, exploring its role in advancing the X-to-image (X2I) generation.
Existing methods in T2I generation, particularly those rooted in diffusion processes, have demonstrated significant success in generating images based on user-provided captions. However, these models suffer from the challenge of tightly coupling text encoders with image decoders, making modifications or upgrades cumbersome. Some references to other T2I approaches include GAN-based methods like Generative Adversarial Nets (GANs), Stack-GAN, Attn-GAN, SD-GAN, DM-GAN, DF-GAN, LAFITE, as well as auto-regressive transformer models like DALL-E and CogView. Additionally, diffusion models like GLIDE, DALL-E 2, and Imagen have been used for image generation within this domain.
T2I generative models have advanced considerably, driven by algorithmic improvements and extensive training data. Diffusion-based T2I models excel in image quality but struggle with controllability and composition, often necessitating prompt engineering for desired outcomes. Another limitation is the predominant training on English text captions, constraining their multilingual utility.
The GlueGen framework introduces GlueNet to align features from various single-modal or multimodal encoders with the latent space of an existing T2I model. Their approach employs a new training objective that utilizes parallel corpora to align representation spaces across different encoders. GlueGen’s capabilities extend to aligning multilingual language models like XLM-Roberta with T2I models, facilitating high-quality image generation from non-English captions. Furthermore, it can align multi-modal encoders, such as AudioCLIP, with the Stable Diffusion model, enabling sound-to-image generation.
GlueGen offers the capability to align diverse feature representations, facilitating the seamless integration of new functionality into existing T2I models. It achieves this by aligning multilingual language models, like XLM-Roberta, with T2I models for generating high-quality images from non-English captions. Additionally, GlueGen aligns multi-modal encoders, such as AudioCLIP, with the Stable Diffusion model, enabling sound-to-image generation. This method also enhances image stability and accuracy compared to vanilla GlueNet, thanks to its objective re-weighting technique. Evaluation is performed using FID scores and user studies.
In conclusion, GlueGen offers a solution for aligning various feature representations, enhancing the adaptability of existing T2I models. By aligning multilingual language models and multi-modal encoders, it expands the capabilities of T2I models to generate high-quality images from diverse sources. GlueGen’s effectiveness is demonstrated through improved image stability and accuracy, aided by the proposed objective re-weighting technique. Moreover, it addresses the challenge of breaking the tight coupling between text encoders and image decoders in T2I models, paving the way for easier upgrades and replacements. Overall, GlueGen presents a promising approach for advancing X-to-image generation functionalities.
Check out the Paper, Github, Project, and SF Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.

Credit: Source link
Comments are closed.