Meta AI Introduces AnyMAL: The Future of Multimodal Language Models Bridging Text, Images, Videos, Audio, and Motion Sensor Data
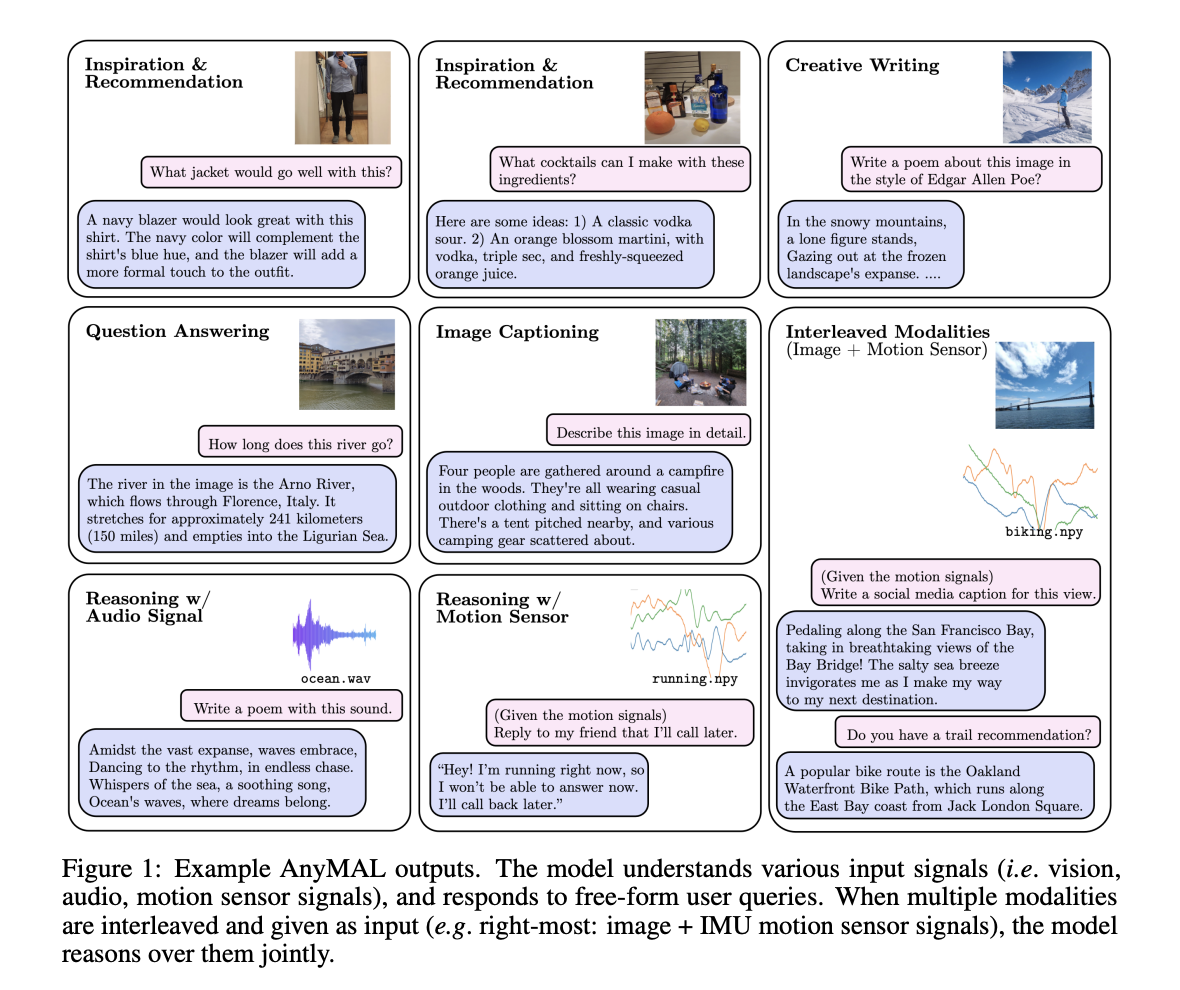
In artificial intelligence, one of the fundamental challenges has been enabling machines to understand and generate human language in conjunction with various sensory inputs, such as images, videos, audio, and motion signals. This problem has significant implications for multiple applications, including human-computer interaction, content generation, and accessibility. Traditional language models often focus solely on text-based inputs and outputs, limiting their ability to comprehend and respond to the diverse ways humans interact with the world. Recognizing this limitation, a team of researchers has tackled this problem head-on, leading to the development of AnyMAL, a groundbreaking multimodal language model.
Current methods and tools in language understanding often need to catch up when handling diverse modalities. However, the research team behind AnyMAL has devised a novel approach to address this challenge. They have developed a large-scale Multimodal Language Model (LLM) that integrates various sensory inputs seamlessly. AnyMAL is not just a language model; it embodies AI’s potential to understand and generate language in a multimodal context.
Imagine interacting with an AI model by combining sensory cues from the world around us. AnyMAL makes this possible by allowing queries that presume a shared understanding of the world through sensory perceptions, including visual, auditory, and motion cues. Unlike traditional language models that rely solely on text, AnyMAL can process and generate language while considering the rich context provided by various modalities.

The methodology behind AnyMAL is as impressive as its potential applications. The researchers utilized open-sourced resources and scalable solutions to train this multimodal language model. One of the key innovations is the Multimodal Instruction Tuning dataset (MM-IT), a meticulously curated collection of annotations for multimodal instruction data. This dataset played a crucial role in training AnyMAL, allowing it to understand and respond to instructions that involve multiple sensory inputs.

One of the standout features of AnyMAL is its ability to handle multiple modalities in a coherent and synchronized manner. It demonstrates remarkable performance in various tasks, as demonstrated by a comparison with other vision-language models. In a series of examples, AnyMAL’s capabilities shine. AnyMAL consistently exhibits strong visual understanding, language generation, and secondary reasoning abilities, from creative writing prompts to how-to instructions and recommendation queries to question and answer.

For instance, in the creative writing example, AnyMAL responds to the prompt, “Write a joke about it,” with a humorous response related to the image of a nutcracker doll. This showcases its visual recognition skills and its capacity for creativity and humor. In a how-to scenario, AnyMAL provides clear and concise instructions on fixing a flat tire, demonstrating its understanding of the image context and its ability to generate relevant language.

In a recommendation query regarding wine pairing with steak, AnyMAL accurately identifies the wine that pairs better with steak based on the image of two wine bottles. This demonstrates its ability to provide practical recommendations grounded in a visual context.

Furthermore, in a question-and-answering scenario, AnyMAL correctly identifies the Arno River in an image of Florence, Italy, and provides information about its length. This highlights its strong object recognition and factual knowledge capabilities.
Concluding Remarks
In conclusion, AnyMAL represents a significant leap forward in multimodal language understanding. It addresses a fundamental problem in AI by enabling machines to comprehend and generate language in conjunction with diverse sensory inputs. AnyMAL’s methodology, grounded in a comprehensive multimodal dataset and large-scale training, yields impressive results in various tasks, from creative writing to practical recommendations and factual knowledge retrieval.
However, like any cutting-edge technology, AnyMAL has its limitations. It occasionally struggles to prioritize visual context over text-based cues, and the quantity of paired image-text data bounds its knowledge. Nevertheless, the model’s potential to accommodate various modalities beyond the four initially considered opens up exciting possibilities for future research and applications in AI-driven communication.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.

Credit: Source link
Comments are closed.