Meta AI Researchers Propose Advanced Long-Context LLMs: A Deep Dive into Upsampling, Training Techniques, and Surpassing GPT-3.5-Turbo-16k’s Performance
The emergence of Large Language Models (LLMs) in natural language processing represents a groundbreaking development. These models, trained on vast amounts of data and leveraging immense computational resources, promise to transform human interactions with the digital world. As they evolve through scaling and rapid deployment, their potential use cases become increasingly intricate and complex. They extend their capabilities to tasks such as analyzing dense, knowledge-rich documents, enhancing chatbot experiences to make them more genuine and engaging, and assisting human users in iterative creative processes like coding and design.
One crucial feature that empowers this evolution is the capacity to effectively process long-context inputs. This means that LLMs should be able to understand and generate text based on substantial amounts of preceding context, which is particularly important for tasks involving lengthy documents, multi-turn conversations, or complex problem-solving.
However, until now, LLMs with robust long-context capabilities have primarily been available through proprietary LLM APIs, leaving a gap in accessible solutions for researchers and developers. Open-source long-context models, while valuable, have often fallen short in their evaluations. Typically, they focus on language modeling loss and synthetic tasks, which, while informative, do not comprehensively showcase their effectiveness in diverse, real-world scenarios. Furthermore, many of these models overlook the need to maintain strong performance on standard short-context tasks, bypassing these evaluations or reporting subpar results.
In response to these challenges, new Meta research presents an approach to constructing long-context LLMs that outshine all existing open-source models. This methodology revolves around continual pretraining from LLAMA 2 checkpoints and utilizes an additional 400 billion tokens to form extensive training sequences. These sequences are designed to capture the essence of long-context understanding. The work offers a range of model variants, including smaller 7B/13B models trained with 32,768-token sequences and larger 34B/70B models trained with 16,384-token sequences.
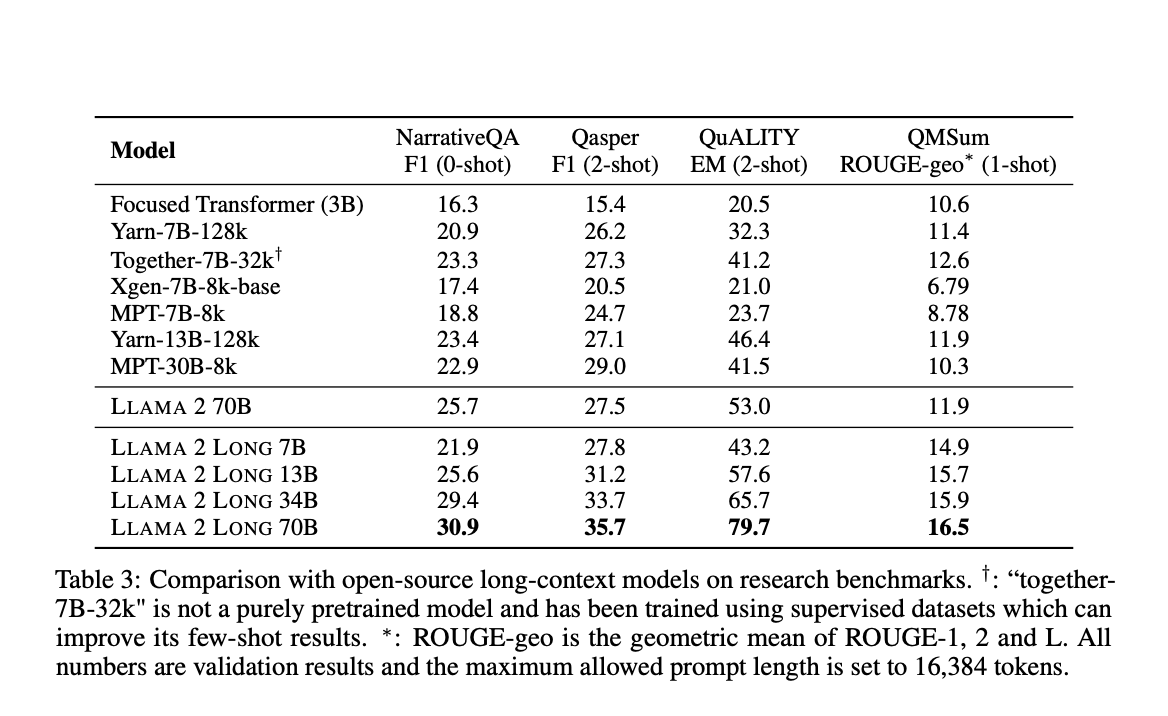
What sets this approach apart is the thoroughness of their evaluation process. Unlike previous studies, the team assesses the model’s performance across multiple dimensions. This includes evaluating their language modeling capabilities, performance on synthetic tasks, and, most importantly, their effectiveness in a wide range of real-world benchmarks. They cover long and short-context tasks to provide a holistic view of the models’ capabilities.
The findings show that the scaling behavior demonstrates the models’ ability to consistently benefit from more extensive contexts and highlights context length as another crucial axis of scaling for LLMs.
Compared to LLAMA 2 on research benchmarks, this method observes significant improvements in long-context tasks and modest enhancements in standard short-context tasks. These improvements are particularly notable in coding, mathematical problem-solving, and knowledge-related tasks. Moreover, the team explores a simple and cost-effective procedure for instruction fine-tuning of continually pretrained long models achieved without human-annotated data. The outcome is a chat model that surpasses the performance of gpt-3.5-turbo-16k on a series of long-context benchmarks,
Overall, the approach represents a significant step towards bridging the gap between proprietary and open-source long-context LLMs. It offers models with superior performance, extensive evaluation across various dimensions, and a deeper understanding of the factors that influence their capabilities. Ultimately, the team hopes to empower researchers and developers to harness the potential of long-context LLMs for a wide array of applications, ushering in a new era of natural language processing.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.