Meta AI Researchers Introduce RA-DIT: A New Artificial Intelligence Approach to Retrofitting Language Models with Enhanced Retrieval Capabilities for Knowledge-Intensive Tasks
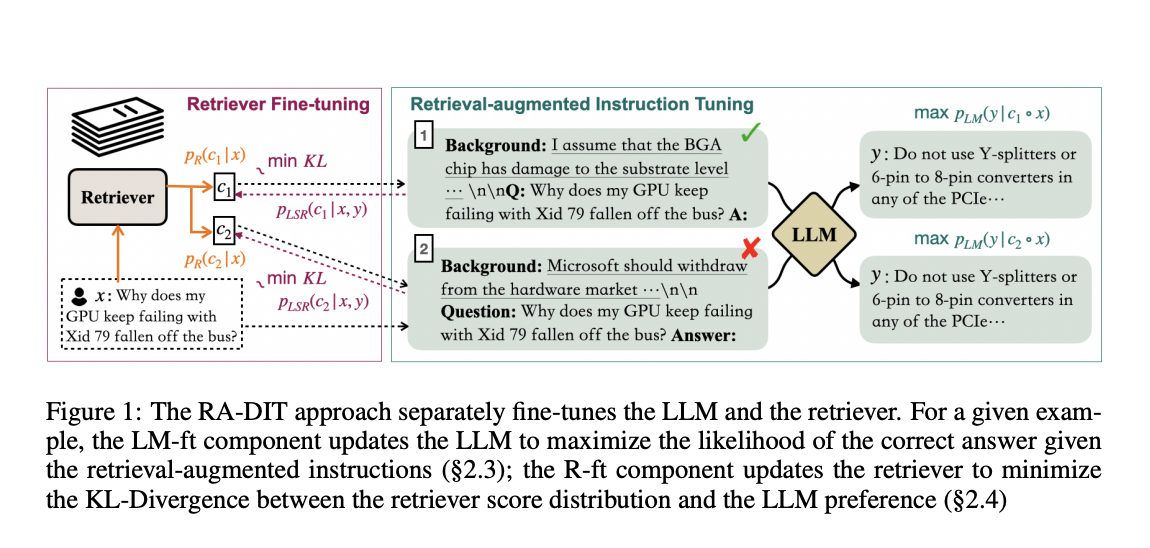
In addressing the limitations of large language models (LLMs) when capturing less common knowledge and the high computational costs of extensive pre-training, Researchers from Meta introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT). RA-DIT is a lightweight fine-tuning methodology designed to equip any LLM with efficient retrieval capabilities. It operates through two distinct fine-tuning stages, each delivering substantial performance enhancements. By optimizing the LM’s use of retrieved information and the retriever’s content relevance, RA-DIT offers a promising solution to enhance LLMs with retrieval capabilities.
RA-DIT provides a lightweight, two-stage fine-tuning method for enhancing LLMs with retrieval capabilities. It optimizes LLMs to use retrieved information better and refines retrievers to provide more relevant results preferred by the LLM. RA-DIT outperforms existing retrieval-augmented models in knowledge-intensive zero and few-shot learning benchmarks, showcasing its superiority in incorporating external knowledge into LLMs for improved performance.
Researchers introduced RA-DIT for endowing LLMs with retrieval capabilities. RA-DIT involves two key fine-tuning stages: first, enhancing a pre-trained LLM’s utilization of retrieved information, and second, refining the retriever to provide more contextually relevant results preferred by the LLM. Their approach employs the LLAMA language model, pretrained on an extensive dataset, and utilizes a dual-encoder-based retriever architecture initialized with the DRAGON model. Additionally, their method mentions using parallel in-context retrieval augmentation for more efficient computation of LLM predictions.
Their method achieves notable performance enhancements, with RA-DIT 65B setting new benchmarks in knowledge-intensive zero-and few-shot learning tasks, surpassing existing in-context Retrieval-Augmented Language Models (RALMs) by a significant margin. RA-DIT demonstrates the efficacy of lightweight instruction tuning in improving RALMs’ performance, particularly in scenarios requiring access to extensive external knowledge sources.
RA-DIT excels in knowledge-intensive zero-and few-shot learning benchmarks, surpassing existing in-context Retrieval-Augmented Language Models (RALMs) by up to +8.9% in the 0-shot setting and +1.4% in the 5-shot location on average. The top-performing model, RA-DIT 65B, showcases substantial improvements in tasks requiring knowledge utilization and contextual awareness. RA-DIT preserves parametric knowledge and reasoning capabilities, outperforming base LLAMA models on 7 out of 8 commonsense reasoning evaluation datasets. Ablation analysis and parallel in-context retrieval augmentation further highlight RA-DIT’s effectiveness in enhancing retrieval-augmented language models, particularly for extensive knowledge access.
In conclusion, their approach introduces RA-DIT, which enhances the performance of pre-trained language models with retrieval capabilities. RA-DIT achieves state-of-the-art results in zero few-shot evaluations on knowledge-intensive benchmarks, surpassing untuned in-context Retrieval-Augmented Language Models and competing effectively with extensively pre-trained methods. It significantly improves performance in tasks requiring knowledge utilization and contextual awareness. RA-DIT 65B outperforms existing models, demonstrating the effectiveness of lightweight instruction tuning for retrieval-augmented language models, especially in scenarios involving vast external knowledge sources.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.