How Can We Efficiently Deploy Large Language Models in Streaming Applications? This AI Paper Introduces the StreamingLLM Framework for Infinite Sequence Lengths
Large Language Models (LLMs) are increasingly used to power natural language processing applications, including code completion, question answering, document summarization, and dialogue systems. Pretrained LLMs must be capable of performing extended sequence creation precisely and quickly to reach their full potential. An ideal ChatBot helper, for instance, can reliably edit the content of recent day-long chats. To generalize to greater sequence lengths than they have been pretrained on, such as 4K for Llama-2, is very difficult for LLM. Because of the attention window during pre-training, LLMs are restricted.
Although significant attempts have been made to increase the size of this window and increase training and inference effectiveness for long inputs, the permissible sequence length still needs to be revised, which prevents permanent deployments. Researchers from MIT, Meta AI and Carnegie Mellon University initially discuss the idea of LLM streaming applications in this study and pose the following query: Two main issues emerge when using LLMs for endless input streams:
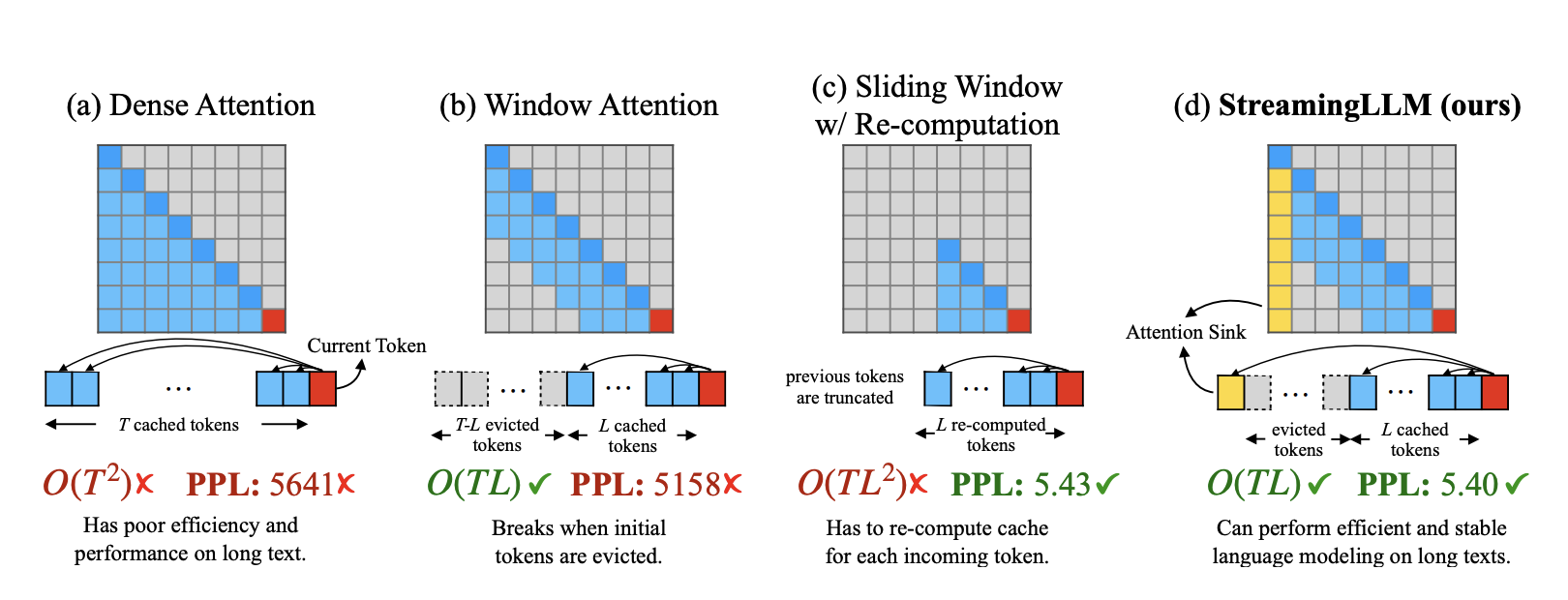
1. Transformer-based LLMs cache the Key and Value states (KV) of all prior tokens during the decoding stage, as shown in Figure 1(a), which may result in excessive memory use and a rise in decoding delay.
2. The performance of existing models suffers when the duration of the sequence exceeds the attention window size determined during pre-training.

Figure 1 compares StreamingLLM to previous techniques. The Tth token (T >> L) is predicted by the language model, which has been pre-trained on texts of length L. (a) Dense Attention has a rising cache capacity and an O(T^2) time complexity. When the text length is more than the pre-training text length, its performance suffers. (b) Window Attention stores the KV of the newest L tokens in its cache. Although performance is good for inference, it rapidly deteriorates when the keys and values of the initial tokens are removed. For each new token, (c) Sliding Window with Re-computation reconstructs the KV states using the L most recent tokens. Although it excels at handling lengthy texts, due to its O(T L^2 ) complexity and quadratic attention in context re-computation, it is incredibly sluggish. (d) For steady attention computation, StreamingLLM retains the attention sink (a few beginning tokens), together with the most recent tokens. It works effectively and consistently with long texts. The Llama-2-13B model is used to calculate perplexities for the first book (65K tokens) in the PG-19 test set.
Window attention is an obvious strategy that keeps a fixed-size sliding window on the KV states of the most recent tokens (Figure 1b). Even merely evicting the KV of the first token causes the model to collapse after the sequence length exceeds the cache capacity, even if it guarantees consistent memory use and decoding performance after the cache is first full. A further tactic is a sliding window with recomputation (Figure 1c), which reconstructs the KV states of recent tokens for each created token. The calculation of quadratic attention within its window makes this technique much slower, even if it performs well, making it unsuitable for real-world streaming applications.
They discover intriguing phenomena of autoregressive LLMs to explain the failure of window attention: a startlingly high attention score is allotted to the initial tokens, regardless of their relevance to the language modeling job. These tokens are referred to as “attention sinks.” They receive significant attention scores while having little semantic value. The Softmax operation, which demands that attention scores add up to one for all contextual tokens, is cited as the cause. As a result, the model must assign these extra attention values to add up to one, even when the current query does not have a good match in many earlier tokens.
Initial tokens are used as attention sinks for a simple reason: they are visible to practically all subsequent tokens due to the nature of autoregressive language modeling, making them easier to train. They suggest StreamingLLM, a straightforward and effective architecture that enables LLMs prepared with a finite attention window to work on text of indefinite duration without fine-tuning, in light of the abovementioned discoveries. Because attention drains have high attention values, StreamingLLM uses this property to keep the attention score distribution reasonably regular. StreamingLLM maintains the KVs of the sliding window and the attention sink tokens (with only four initial tokens needed) to anchor the attention computation and stabilize the model’s performance.
Models like Llama-2-B, MPT-B, Falcon-B, and PythiaB can accurately represent 4 million tokens with the help of StreamingLLM, and maybe much more. StreamingLLM achieves up to 22.2 speedups compared to the only practical baseline, sliding window with recomputation, realizing the streaming usage of LLMs. Finally, they show that language models may be pre-trained to require only a single attention sink token for streaming deployment, confirming their attention sink hypothesis. They propose that a selected attention sink can be implemented as an additional learnable token at the start of each training sample. Introducing this single sink token maintains the model’s performance in streaming instances by pre-training language models with 160 million parameters from scratch. This contrasts with vanilla models, which call for reintroducing several initial tokens as attention sinks to maintain the same degree of performance.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.