Researchers from Google and John Hopkins University Reveal a Faster and More Efficient Distillation Method for Text-to-Image Generation: Overcoming Diffusion Model Limitations

By producing high-quality and varied outcomes, text-to-image diffusion models trained on large-scale data have considerably dominated generative tasks. In a recently developed trend, typical image-to-image transformation tasks like image alteration, enhancement, or super-resolution are guided by the generated outcomes with external image conditions using diffusion before pre-trained text-to-image generative models. The diffusion prior introduced by pre-trained models is proven to significantly enhance the visual quality of the conditional picture production outputs among various transformation procedures. Diffusion models, on the other hand, greatly rely on an iterative refining process that frequently necessitates many iterations, which can take time to complete effectively.
Their dependency on the number of repetitions grows further for high-resolution picture synthesis. For instance, even with sophisticated sampling techniques, excellent visual quality in state-of-the-art text-to-image latent diffusion models often needs 20–200 sample steps. The slow sampling period severely restricts the above-mentioned conditional diffusion models’ practical applicability. Most recent attempts to speed up diffusion sampling use distillation techniques. These techniques greatly speed up sampling, finishing it in 4–8 steps while little affecting generative performance. Recent research demonstrates that these techniques may also be used to condense large-scale text-to-image diffusion models that have already been trained.
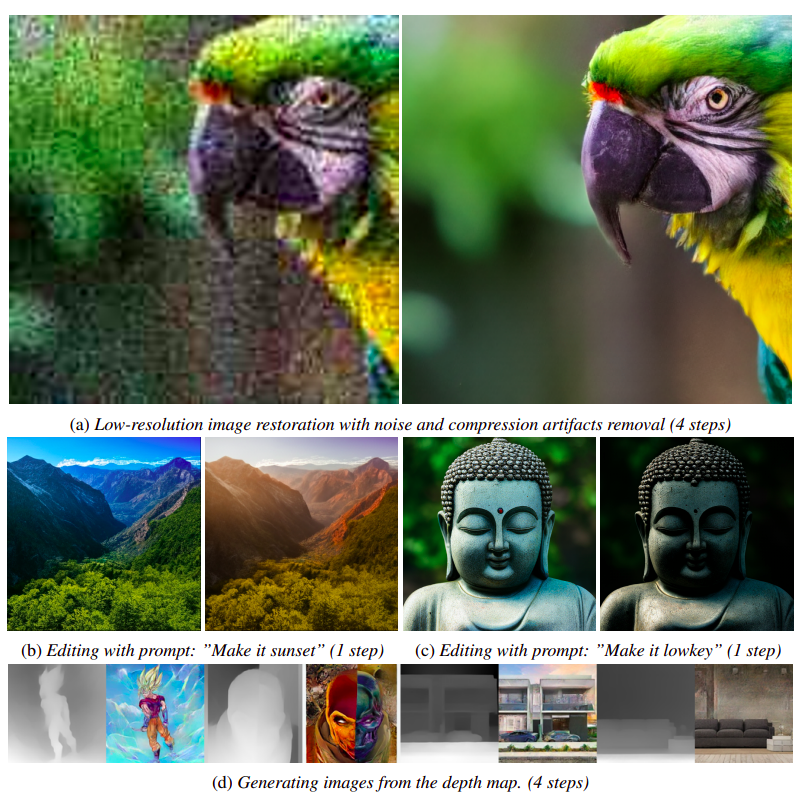
They provide the output of our distilled model in a variety of conditional tasks, illustrating the capacity of our suggested approach to replicate diffusion priors in a condensed sampling period.
Based on these distillation methods, a two-stage distillation process—either distillation-first or conditional finetuning-first—can be utilized to distil conditional diffusion models. When given the same sampling period, these two techniques provide results that are typically superior to those of the undistilled conditional diffusion model. However, they have differing benefits regarding cross-task flexibility and learning difficulty. In this work, they present a fresh distillation method for extracting a conditional diffusion model from an unconditional diffusion model that has already been trained. Their approach features a single stage, beginning with the unconditional pretraining and ending with the distilled conditional diffusion model, as opposed to the traditional two-stage distillation technique.
Figure 1 illustrates how their distilled model can forecast high-quality results in just one-fourth of the sampling steps by taking cues from the given visual settings. Their technique is more practical since this streamlined learning eliminates the need for the original text-to-image data, which was necessary in earlier distillation processes. They also avoid compromising the diffusion prior in the pre-trained model, a typical mistake when using the finetuning-first method in its first stage. When given the same sample time, extensive experimental data demonstrate that their distilled model performs better than earlier distillation techniques in both visual quality and quantitative performance.
A field that needs further research is parameter-efficient distillation techniques for conditional generation. They show that their approach provides a novel distillation mechanism that is parameter-efficient. By adding a few more learnable parameters, it can convert and speed up an unconditional diffusion model for conditional tasks. Their formulation, in particular, enables integration with several already-in-use parameter-efficient tuning techniques, such as T2I-Adapter and ControlNet. Using both the newly added learnable parameters of the conditional adaptor and the frozen parameters of the original diffusion model, their distillation technique learns to reproduce diffusion priors for dependent tasks with minimal iterative revisions. This new paradigm has greatly increased the usefulness of several conditional tasks.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.