From Specialists to General-Purpose Assistants: A Deep Dive into the Evolution of Multimodal Foundation Models in Vision and Language
The computer vision community faces a wide range of challenges. Numerous seminar papers were discussed during the pretraining era to establish a comprehensive framework for introducing versatile visual tools. The prevailing approach during this period involves pretraining models on large volumes of problem-related data and then transferring them to various real-world scenarios related to the same problem type, often using zero- or few-shot techniques.
A recent Microsoft study provides an in-depth look at the history and development of multimodal foundation models that exhibit vision and vision-language capabilities, particularly emphasizing the shift from specialized to general-purpose helpers.
According to their paper, there are three primary categories of instructional strategies discussed:
Label supervision: Label supervision uses previously labeled examples to train a model. Using ImageNet and similar datasets has proven the effectiveness of this method. We can access a large, noisy dataset from the internet, images, and human-created labels.
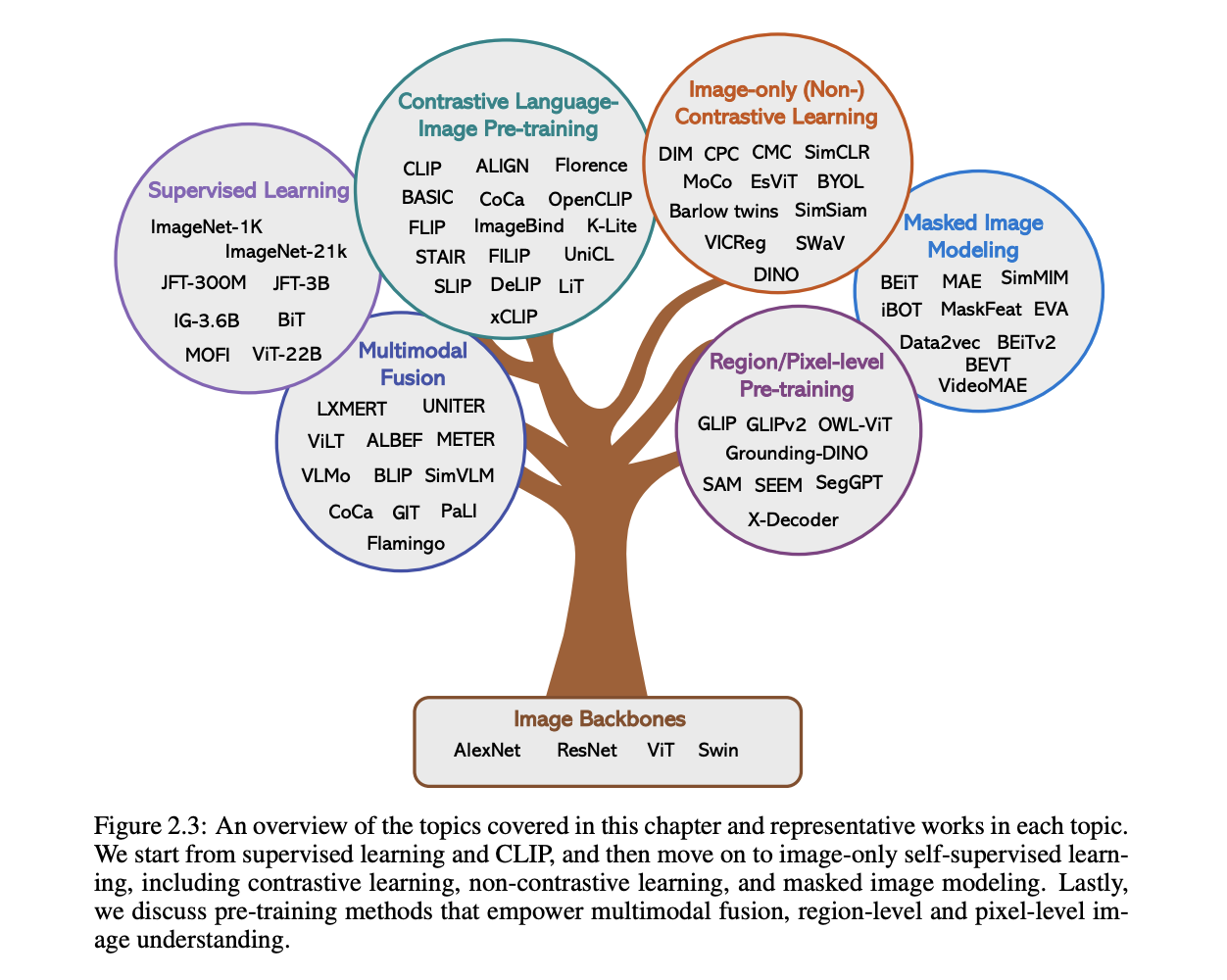
Also known as “language supervision,” this strategy uses unsupervised text signals, most frequently in image-word pairs. CLIP and ALIGN are examples of pre-trained models for comparing image-text pairs using contrastive loss.
Image-Only Self-Supervised Learning: This technique relies solely on visuals as a source of supervision signals. Masked image modeling, non-contrastive, and contrast-based learning are all viable options.
The researchers looked at how several approaches to visual comprehension, such as those used for picture captioning, visual question answering, region-level pre training for grounding, and pixel-level pre training for segmentation, can be integrated to obtain the best results.
Multimodal Foundation Models
The ability to comprehend and interpret data presented in multiple modalities, such as text and images, sets multimodal foundation models apart. They make possible a variety of tasks that would otherwise necessitate substantial data collection and synthesis. Important multimodal conceptual frameworks include the ones listed below.
- CLIP (Contrastive Language-Image Pretraining) is a ground-breaking technique for discovering a common image and text embedding space. It’s capable of things like image-text retrieval and zero-shot categorization.
- BEiT (BERT in Vision) adapts BERT’s masked image modeling technique for usage in the visual domain. Tokens in masked images can be predicted so that image converters can move on to other duties.
- CoCa (Contrastive and Captioning Pretraining) combines contrastive learning with captioning loss for pre-training an image encoder. Observing the completion of a multimodal task is now a realistic possibility thanks to the Paraphrase Image Captioning System.
- UniCL (Unified Contrastive Learning) allows unified contrastive pretraining on image-text and image-label pairs by extending CLIP’s contrastive learning to image-label data.
- MVP (Masked Image Modeling Visual Pretraining) is a method for pretraining vision transformers that uses masked images and high-level feature objectives.
- To improve the precision of MIM, EVA (Exploiting Vision-Text Alignment) uses image features from models like CLIP as target features.
- BEiTv2 improves upon BEiT by incorporating a DINO-like self-distillation loss to promote the acquisition of global visual representations in learning.
Computer vision and natural language processing applications have benefited greatly from the enhanced model interpretation and processing made possible by these multimodal foundation models.
Their study further looks into “Visual Generation,” discovering that text-to-image generation models have been the backbone of picture synthesis. These models have been successfully extended to permit finer-grained user control and customization. The availability and generation of massive amounts of data related to the problem are crucial factors in implementing these multimodal foundation models.
Introduction to T2I ProductionT2I generation attempts to provide visuals corresponding to textual descriptions. These models are often trained on image-and-text pairs, with the texts providing input conditions and the photos acting as the desired output.
The T2I model is explained with examples from Stable Diffusion (SD) throughout the book. SD is a well-liked open-source T2I model because of its cross-attention-based image-text fusion and diffusion-based creation method.
Denoising Unified Neural Network (U-Net), Text Encoder, and Image Variational Autoencoder (VAE) are the three main components of SD. The VAE encodes images, the TEN encodes text conditions, and the Denoising U-Net predicts noise in the latent space to generate fresh images.
Improving spatial controllability in T2I generation is examined, and one approach is to allow for more spatial conditions to be input alongside text, such as region-grounded text descriptions or dense spatial requirements like segmentation masks and key points. It examines how T2I models like ControlNet may use elaborate constraints like segmentation masks and edge maps to manage the imaging production process.
Recent developments in text-based editing models are presented; these models may modify photos in line with textual instructions, eliminating the need for user-generated masks. T2I models can better follow text prompts thanks to Alignment tuning, similar to how Language models are trained for improved text generation. Possible solutions are addressed, including those based on reinforcement learning.
There won’t be any need for separate image and text models in the future, thanks to the rising popularity of T2I models with integrated alignment solutions, as mentioned in the text. In this study, the team suggested a unified input interface for T2I models that would allow for the concurrent input of images and text to assist tasks like spatial control, editing, and concept customization.
Alignment with Human Intent
To ensure that T2I models produce images that correspond well with human intent, the research underlines the requirement of alignment-focused loss and rewards, analogous to how Language Models are fine-tuned for specific tasks. The study explores the potential benefits of a closed-loop integration of content comprehension and generation in the context of multimodal models, which mix understanding and generation tasks. Unified vision models are built at different levels and for different activities using the LLM principle of unified modeling.
Open-world, unified, and interactive vision models are the current focus of the vision research community. Still, there are some fundamental gaps between the language and visual spheres.
- Vision is different from language in that it captures the world around us using raw signals. Creating compact “tokens” from raw data involves elaborate tokenization processes. This is easily accomplished in the language domain with the help of multiple established heuristic tokenizers.
- Unlike language, visual data is not labeled, making it difficult to convey meaning or expertise. Semantic or geospatial, the annotation of visual content is always labor-intensive.
- There is a wider variety of visual data and activities than there is with verbal data.
- Lastly, the cost of archiving visual data is much higher than data in other languages. Compared to GPT-3, the 45 TB of training data needed for the ImageNet dataset (which contains 1.3 million images) is only a few hundred gigabytes more expensive. Regarding video data, the storage cost is close to that of the GPT-3 training corpus.
Differences between the two perspectives are debated in the later chapters. Out in the real world using computer vision. Because of this, the existing visual data utilized for training models falls short of accurately representing the whole diversity of the real world. Despite the efforts to build open-set vision models, there are still significant challenges in dealing with novel or long-tail events.
According to them, some laws that scale with the vision are required. Earlier studies have demonstrated that the performance of large language models improves steadily with increases in model size, data scale, and computes. At larger scales, LLMs reveal some remarkable new characteristics. However, how best to grow vision models and use their emergent properties is still a mystery. Models that use either visual or linguistic input. There has been less and less of a separation between the visual and verbal realms in recent years. However, given the intrinsic differences between vision and language, it is questionable if a combination of moderate vision models and LLMs is adequate to manage most (if not all) of the issues. However, creating a fully autonomous AI vision system on par with humans is still a ways off. Using LLaVA and MiniGPT-4 as examples, the researchers explored the background and powerful features of LMM, studied instruction tuning in LLMs, and showed how to build a prototype using open-source resources.
The researchers hope that the community keeps working on prototypes for new functionalities and evaluation techniques to lower the computational barriers and make large models more accessible, and still focus on scaling success and studying new emerging properties.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.