Researchers from Princeton and Meta AI Introduce MemWalker: A New Method that First Processes the Long Context into a Tree of Summary Nodes
Adopting the Transformer architecture with self-attention and increases in model size and pre-training data has led to significant progress in large language models (LLMs). Users want to use longer input sequences during inference more frequently as LLMs improve capacity. As a result, there is an increasing need for services that facilitate the analysis of lengthy texts, such as legal or scientific studies, and the management of lengthy conversations. Longer context processing time is very useful when dealing with such a massive volume of information consumption as these tasks require.
Despite the progress, the self-attention mechanism’s limitations become more obvious as the length of a sequence increases the amount of memories it must keep track of. Several methods have been used to deal with this issue, such as developing more compact and effective attention schemes, fine-tuning with extrapolated or interpolated positional embeddings, using recurrence to carry forward information from one text segment into the next, and retrieving pertinent passages. However, these methods still have inherent constraints. No matter how far you drag the slider, the context window always stays the same size, and not every spot has the same weight. Although recurrence can handle sequences of indefinite length, it frequently forgets details from previous parts of the sequence.
Instead of analyzing the full sequence at once, researchers from Princeton University and Meta AI created a radically new method that approaches the model with a finite context window as an interactive agent, thereby resolving the problems above. To achieve this goal, they present MEMWALKER, a method that guides the model through the lengthy text in an iterative LLM-based manner.
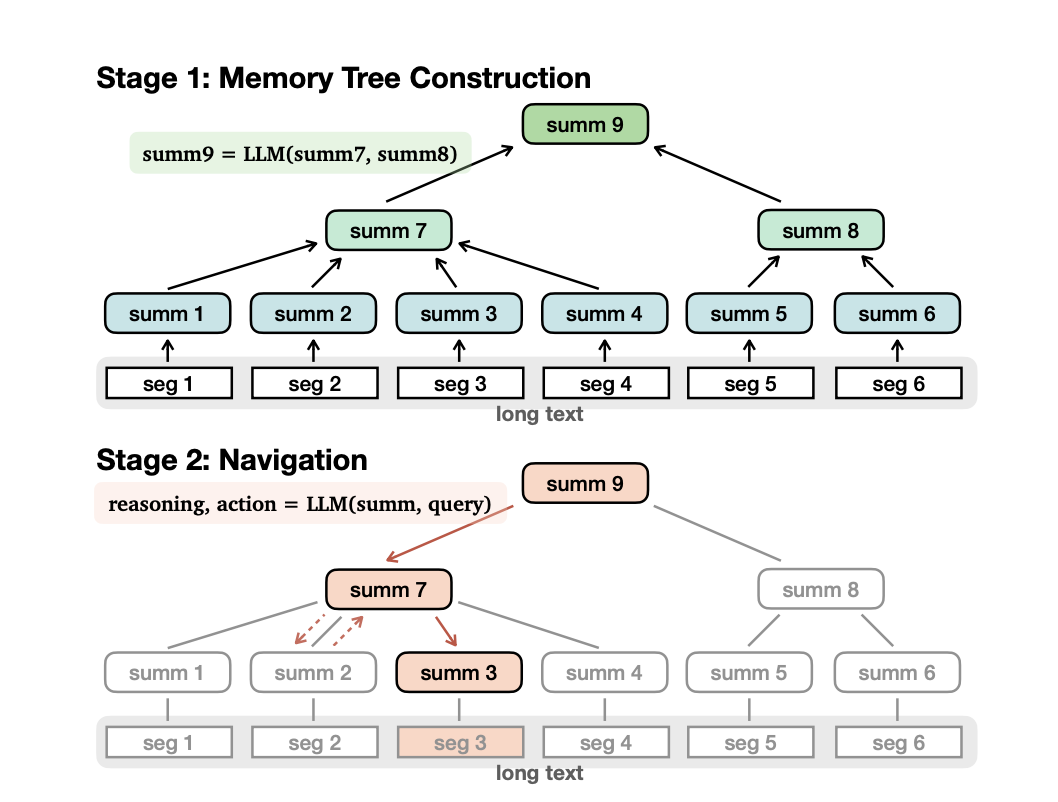
MEMWALKER is a two-step process that involves:
- Building a memory tree
- Using that tree to guide the way.
The lengthy material is broken into manageable pieces in the first phase that the LLM can process. The LLM then condenses the information from each segment into a unified summary node. The tree structure is constructed from these summary nodes and subsequently summarized into higher-level summary nodes. When processing a user inquiry, the LLM will return to the tree’s beginning. It looks at each tree branch and analyzes the text to find the path that answers the question. This allows MEMWALKER to process texts rapidly and to identify the crucial parts of a long text in its native language without requiring any fine-tuning on the part of the user.
In their analysis of MEMWALKER, the team finds that the system outperforms recurrence, retrieval, and vanilla LLM baselines when asked to answer three different types of extended context questions. Other open long context systems that can handle 8,000 to 16,000 tokens couldn’t compare to MEMWALKER’s performance. They evaluate MEMWALKER’s performance, demonstrating that it can reason about navigation decisions, use working memory while traversing, and rectify mistakes committed in the early stages of navigation.
The team also discussed three significant shortcomings with MEMWALKER:
- The memory tree generation might not scale very well if the sequence gets long.
- The study’s results show that the LLM must be large (over 70B) and instruction-tuned for MEMWALKER to be effective.
- MEMWALKER’s interactive reading capabilities are limited to zero-shot prompting, and it does not use fine-tuning in any way.
Nevertheless, the team believes that MEMWALKER paves the way for a lot of exciting research in the future, including expanding its use to data structures other than trees and optimizing its performance for the interactive reading task.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.