How Can Transformers Handle Longer Inputs? CMU and Google Researchers Unveil a Novel Approach (FIRE): A Functional Interpolation for Relative Position Encoding
Transformer-based Language Models have uplifted the domain of Natural Language Processing (NLP) in recent years. Their capacity to comprehend and produce text that is human-like has resulted in ground-breaking improvements across a range of NLP tasks. However, these models have a serious flaw: when exposed to input sequences longer than those encountered during training, their performance usually declines noticeably. The need to find ways to increase their ability to manage lengthier contexts in real-world applications has been spurred by this restriction.
Although the Transformer architecture itself is theoretically capable of handling different input durations, the model’s efficacy when dealing with longer inputs can be limited by the position encoding used during training. To address these challenges, a team of researchers from Carnegie Mellon University, Google Research, and Google DeepMind has introduced a unique approach called Functional Interpolation for Relative Positional Encoding (FIRE). The purpose of FIRE is to improve Transformers’ ability to generalize over long context lengths. This has been made possible by a brand-new method called progressive interpolation with functional relative position encoding.
The basic idea of FIRE is to give Transformer models a more flexible means of comprehending token placements within a sequence. FIRE offers a dynamic and learnable mechanism for encoding positional information in place of a predefined position encoding scheme. This strategy is important because it enables the model to modify and alter its comprehension of location in response to the particular context and sequence length that it encounters.
FIRE’s capacity to conceptually describe some of the widely used relative position encoding techniques, like Kerple, Alibi, and T5’s Relative Positional Encoding (RPE), is one of its main advantages. This indicates that FIRE preserves compatibility with current methods and models while simultaneously providing enhanced performance.
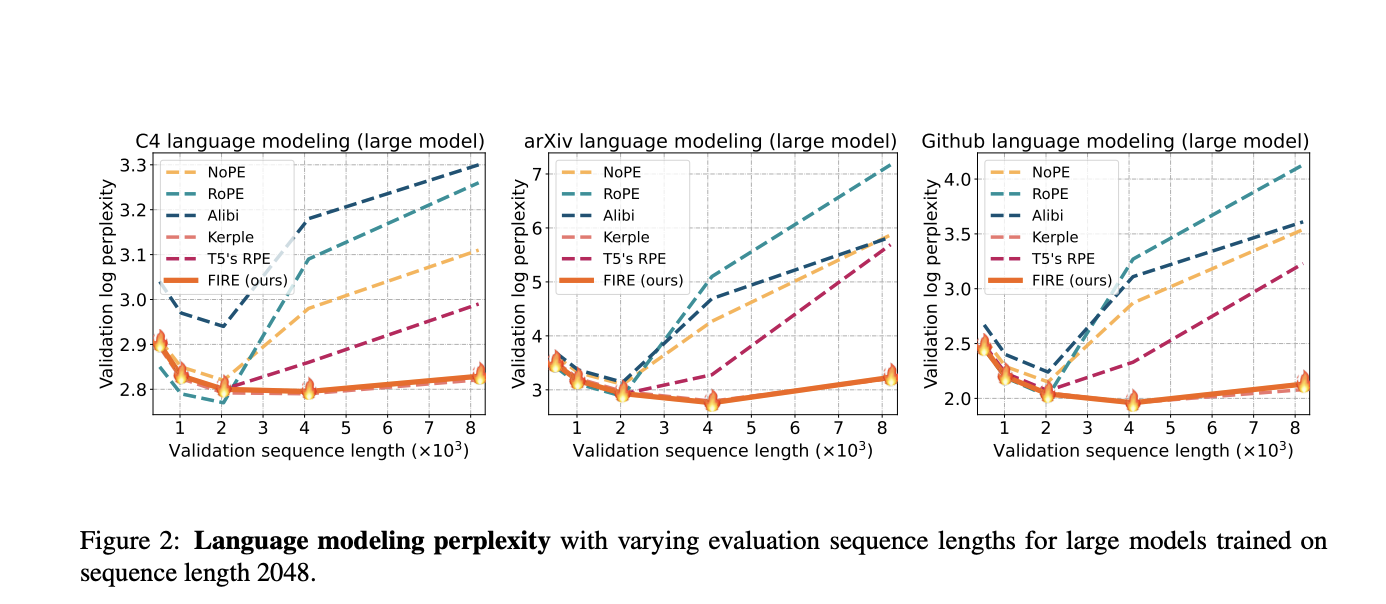
A number of experiments have been conducted to assess FIRE-equipped models’ performance in situations where prolonged context comprehension is crucial. This assessment covers a range of benchmarks, such as zero-shot language modeling and problems with long textual inputs. Improved models using this new method have shown better performance in terms of generalization when handling lengthier contexts. This implies that when presented with longer sequences, individuals are more capable of comprehending and producing meaningful text—a skill that is extremely useful in practical settings.
The main contributions have been summarized by the researchers as follows.
- A new functional relative positional encoding technique called FIRE has been introduced. FIRE can represent popular position encoding methods, such as Alibi, Kerple, and T5’s RPE, bringing these methods together.
- FIRE outperforms current techniques in zero-shot and fine-tuning scenarios on a variety of datasets and benchmarks, exhibiting high-length generalization performance. It even outperforms the best baseline by 2.28 perplexity points on the C4 language modeling problem, demonstrating its usefulness. It outperforms other techniques by an average of more than 1 point on the SCROLLS long text test.
- FIRE’s versatility for different tasks is enhanced by its capacity to capture both local and anti-local position biases, as demonstrated by the visualizations of learned position embeddings.
In conclusion, FIRE offers a great resolution to a persistent issue with Transformer models. Relative position encoding is approached in a flexible and learnable way, enabling these models to continue operating at high performance even when faced with input sequences of previously unheard-of length.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.