Can Compressing Retrieved Documents Boost Language Model Performance? This AI Paper Introduces RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation
Optimizing their performance while managing computational resources is a crucial challenge in an increasingly powerful language model era. Researchers from The University of Texas at Austin and the University of Washington explored an innovative strategy that compresses retrieved documents into concise textual summaries. By employing both extractive and abstractive compressors, their approach successfully enhances the efficiency of language models.
Efficiency enhancements in Retrieval-Augmented Language Models (RALMs) are a focal point, focusing on improving the retrieval components through techniques like data store compression and dimensionality reduction. Strategies to reduce retrieval frequency include selective retrieval and the utilization of larger strides. Their paper “RECOMP” contributes a novel approach by compressing retrieved documents into succinct textual summaries. Their approach not only reduces computational costs but also enhances language model performance.
Addressing the limitations of RALMs, their study introduces RECOMP (Retrieve, Compress, Prepend), a novel approach to enhance their efficiency. RECOMP involves compressing retrieved documents into textual summaries before in-context augmentation. Their process utilizes both an extractive compressor to select pertinent sentences from the documents and an abstractive compressor to synthesize information into a concise summary.
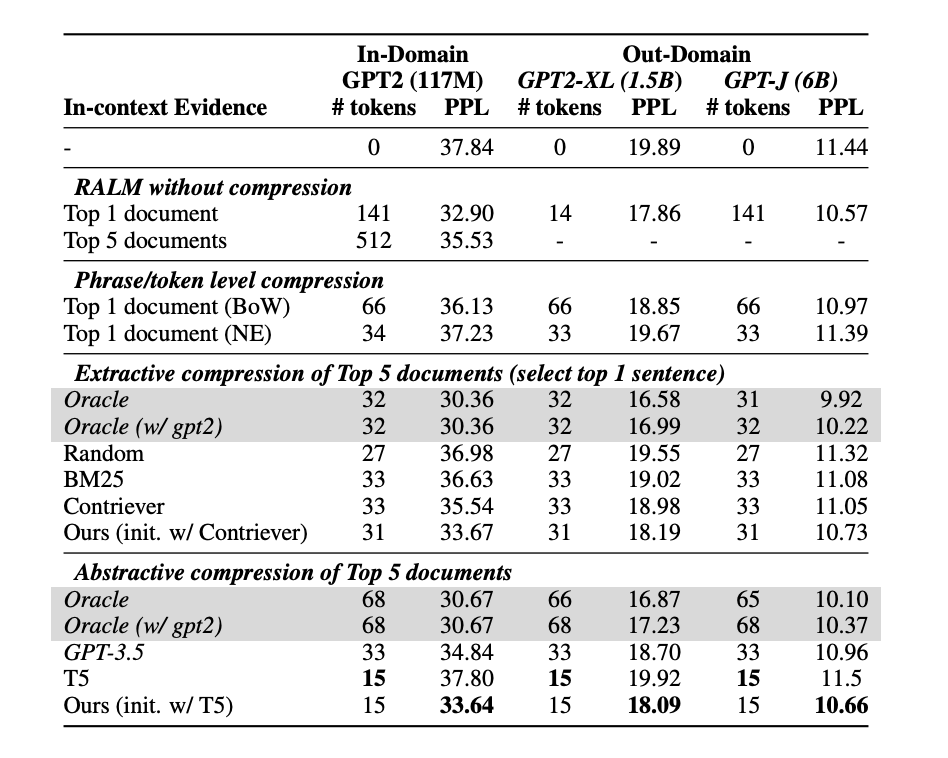
Their method introduces two specialized compressors, an extractive and an abstractive compressor, designed to enhance language models’ (LMs) performance on end tasks by creating concise summaries from retrieved documents. The extractive compressor selects pertinent sentences, while the abstractive compressor synthesizes data from multiple documents. Both compressors are trained to optimize LM performance when their generated summaries are added to the LM’s input. Evaluation includes language modeling and open-domain question-answering tasks, and transferability is demonstrated across various LMs.
Their approach is evaluated on language modeling and open-domain question-answering tasks, achieving a remarkable 6% compression rate with minimal performance loss, surpassing standard summarization models. The extractive compressor excels in language models, while the abstractive compressor performs best with the lowest perplexity. In open-domain question answering, all retrieval augmentation methods enhance performance. Extractive oracle leads and DPR performs well among extractive baselines. The trained compressors transfer across language models in language modeling tasks.
RECOMP is introduced to compress retrieved documents into textual summaries, enhancing LM performance. Two compressors, extractive and abstractive, are employed. The compressors are effective in language modeling and open-domain question-answering tasks. In conclusion, compressing retrieved documents into textual summaries improves LM performance while reducing computational costs.
Future research directions, including adaptive augmentation with the extractive summarizer, improving compressor performance across different language models and tasks, exploring varying compression rates, considering neural network-based models for compression, experimenting on a broader range of functions and datasets, assessing generalizability to other domains and languages, and integrating other retrieval methods like document embeddings or query expansion to enhance retrieval-augmented language models.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.